
背景
茶多酚是茶叶的重要组成部分,也是生物活性化学物质的重要来源,具有抗氧化、抗癌、抗菌、抗炎和抗动脉硬化的能力,在医药和食品工业中发挥着重要作用。高光谱成像技术是基于大量窄波段的图像数据技术。它将成像技术与光谱技术相结合,检测目标的二维几何空间和一维光谱信息,已被广泛应用于农产品质量检测。
基于高光谱技术建立的模型结果受多种因素的影响。特征数据预处理方法是影响分析结果的主要因素。常见的光谱数据预处理方法包括正交信号校正(OSC)、一阶导数(FD)、二阶导数(SD)、多元散射校正(MSC)、标准正态变量变换(SNVT)、Savitzky-Gola滤波(SG)。结果表明,这些方法可以减少外界因素的影响,在一定程度上提高检测的准确性。
光谱特征波段的选择是影响模型结果的另一个重要因素。有效地选择特征波段可以节省计算资源,提高模型性能。近年来,研究人员提出了许多特征波段选择方法,如区间偏最小二乘(iPLS)、协同区间偏最小二乘(siPLS)、后向区间偏最小二乘(biPLS)。这些特征选择算法将所有特征划分为若干个区间,然后通过迭代选取区间中效果较好的一小部分作为特征集合。然而,通过这种“捆绑”方法选择的光谱特征可能会遗漏一些重要特征。
为了避免手动数据分割引起的偏差,有许多计算方法可用于样本选择,如随机选择(RS),Kennard-Stone(KS)或基于联合x-y距离(SPXY)的样本集分割算法。
本研究旨在探讨基于高光谱图像技术的茶多酚含量快速无损在线检测的可行性。采用不同的数据预处理方法对采集到的茶叶高光谱数据进行处理。本文通过建立模型并对建模结果进行分析,选择了*佳的预处理方法。
试验设计
四川农业大学康志亮团队共选出三个级别的雅安藏茶,获取其茶多酚含量后,用SPXY算法对数据集进行划分(表1)。利用江苏双利合谱公司研制的GaiaSorter高光谱分选仪获得了藏茶的高光谱数据,其有效光谱范围为387 ~ 1035nm,光谱分辨率为2.8 nm,光谱通道为256条。把茶叶均匀地铺在一个容器里(大约65厘米 × 65厘米)。高光谱采集系统如图1所示。由于暗电流的影响,最终420 ~ 1010 nm波段被保留作为原始光谱数据。
表1 基于 SPXY 算法的茶多酚含量统计及样品分配结果
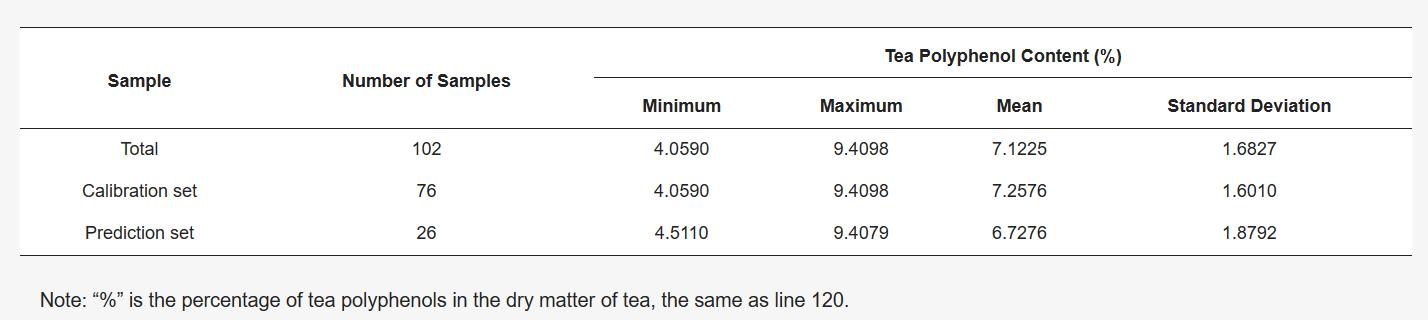
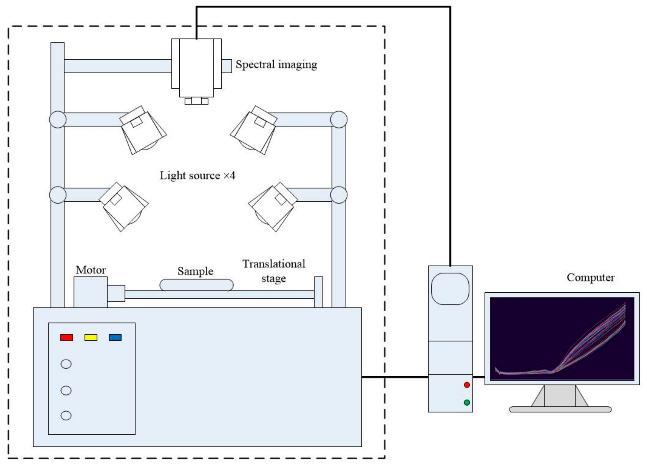
图1 高光谱成像系统示意图
随机噪声通常是在获取光谱时由外界环境、仪器响应和其他与被测样品性质无关的因素产生的,并且光谱数据出现无序波动。因此,本文采用了SG、MSC、SNVT、FD、SD和Z分数标准化(ZSS)六种预处理算法来消除原始光谱数据中的噪声。
本研究使用的SPXY算法是由KS(Kennard-Stone)算法发展而来。KS算法将所有样本看作校准集的候选样本,并选择进入校准集的欧几里得度量最大的两个样本。然后,通过计算剩余样本与校准集中已知样本之间的欧几里得度量,选择最接近选定样本的两个样本并将其放入校准集中,重复上述步骤,直到样本数达到设定值。在SPXY计算样本距离时,同时考虑了样本标号(Y)和样本特征(X)。
所获得的高光谱数据往往包含大量冗余信息,这将对最终建模的准确性和效率产生一定的影响。本研究使用六种方法,梯度提升(GB)、自适应提升(AdaBoost)、随机森林(RF)、分类提升(CatBoost)、LightGBM和XgBoost来选择高光谱特征波段。模型中使用了随机森林回归(RFR)、分类提升回归(CatBoostR)、LightGBM回归(LightGBMR)、XGBoost回归(XGBoostR)和模型集成策略用于预测茶多酚。
结论
梯度提升回归(GBR)用于建模和预测原始数据和预处理的光谱数据。基于不同预处理算法和不同样本划分算法的建模结果如图2所示。如图2a所示,校准集的R2均大于0.96。RAW-KS-GBR模型效果*好。FD-KS-GBR模型校准集R2*大的,为0.9857,但测试集R2最小,仅为0.6490,表明FD-KS-GBR模型存在严重的过拟合问题。图2b是基于SPXY划分数据集的建模结果。通过FD和SD预处理光谱数据建立的模型校准集在0.98以上,但测试集R2不超过0.88。
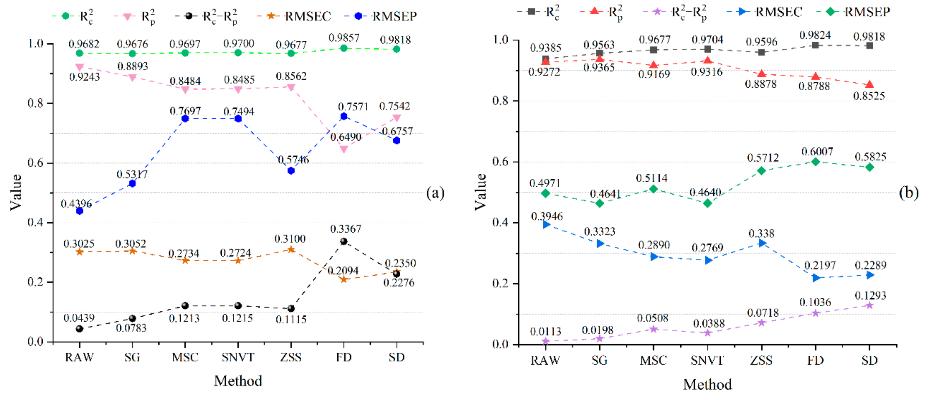
图2 不同输入下GBR模型的预测结果。基于KS划分数据集的建模结果(a)、基于SPXY划分数据集的建模结果(b)。
KS算法比SPXY算法建立的模型更容易出现过拟合,因此SPXY-GBR模型总体上优于KS-GBR模型。基于图2,比较两种不同的数据集划分方法和六种不同的预处理算法建模结果,效果较好的模型是RAW-KS-GBR、SG-SPXY-GBR和SNVT-SPXY-GBR。SG-SPXY-GBR具有最高的测试集R2,为0.9365,其校准集R2也达到0.9563。这表明,以SG为预处理算法,SPXY为样本分割法建立的模型不仅精度高,而且具有更好的鲁棒性。综上所述,最终选择SG算法对藏茶原始高光谱数据进行预处理。原始光谱曲线RAW和SG预处理后的光谱曲线如图3所示。
图3 藏茶光谱曲线。原始数据(a);通过SG算法预处理的数据(b);(c)图为(a)中红框的放大视图;(d)图为(b)中红框的放大视图。
SG算法预处理后的数据噪声有了一定程度的改善,但数据中仍有大量与茶多酚含量预测无关的信息。如果不进一步提取特征,高维数据无疑会影响模型的准确性和鲁棒性。本研究采用GB、AdaBoost、RF、CatBoost、LightGBM和XGBoost这六种算法选择前30个最重要光谱特征(图4)。RF和CatBoost以522.66 nm波长为第二重要特征,而XGBoost以564.55 nm波长为*一重要特征,在GB中仅排名第五,在AdaBoost中排名第四,在RF中排名第七。不同算法提取的特征波长大多分布在420 ~ 700 nm之间。试验结果表明,不同算法提取的特征波长不同,但也有一定的共性。上述六种算法提取的特征将作为后续回归预测算法的输入。
表2展示了不同模型的全波段预测结果。CatBoostR模型具有最高的准确度,在校准和测试集上的R2分别为0.9578和0.9493。RFR模型预测效果较差,校准R2仅为0.9040。
本研究以RFR、LightGBM和XGBoostR为三个基础学习模型,以CatBoostR为元学习模型,建立了一个新的stacking预测模型(图5)。表3展示了不同模型的预测结果。与全波段建模结果相比,即使特征维数降低,模型性能也没有相应降低。优选特征在一定程度上提高了建模精度,并进一步提高了模型鲁棒性。CatBoostR模型的预测精度普遍可以接受,RMSEC小于0.35,RMSEP小于0.45。CatBoost + CatBoostR模型的RMSEC和RMSEP值最接近。因此,该模型被认为是四个独立模型中*好的。本文建立的stacking模型中以CatBoost算法提取的特征作为输入的模型效果*优。图6a是CatBoost + stacking模型对藏茶茶多酚含量的预测结果。由于茶多酚含量在7%左右的样本数量较少,SPXY没有在该值附近分配测试集。因此,在SPXY划分的数据集中,选择对应于校准集中茶多酚含量为7.2671%的样品作为测试样本之一,选择对应于测试集中茶多酚含量为8.7892%的样品作为校准样本之一。如果替换的数据被输入到CatBoost + stacking模型中,校准集R2为0.9686,RMSEC为0.2833,测试集R2为0.9577,RMSEP为0.3703。
综上结果表明,新建立的stacking预测模型比个体回归模型性能更优,可实现藏茶茶多酚含量的准确预测。
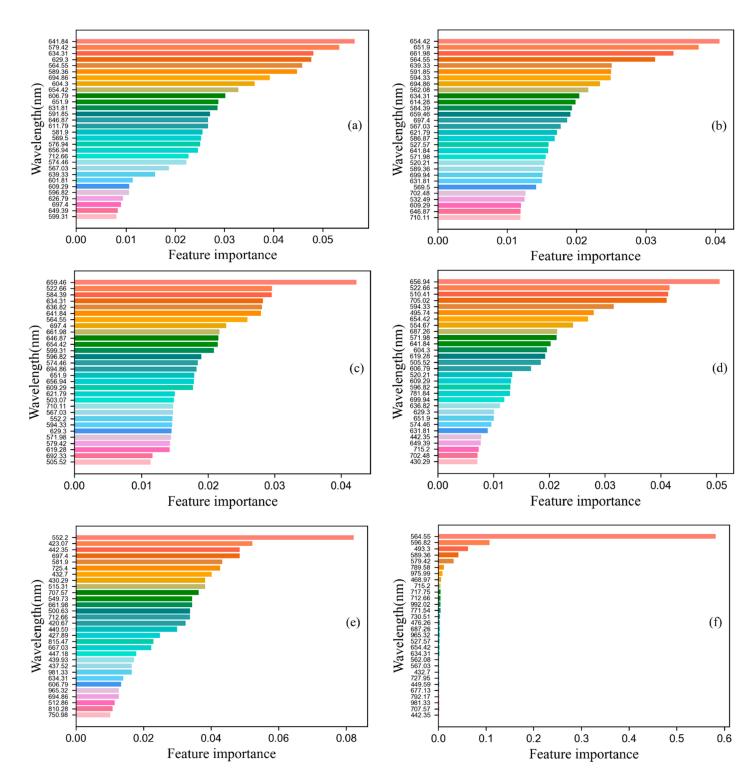
图4 由不同算法选择的特征波段。GB(a);AdaBoost(b);RF(c);CatBoost(d);LightGBM(e)和XGBoost(f)。
表2 基于全波段的预测结果

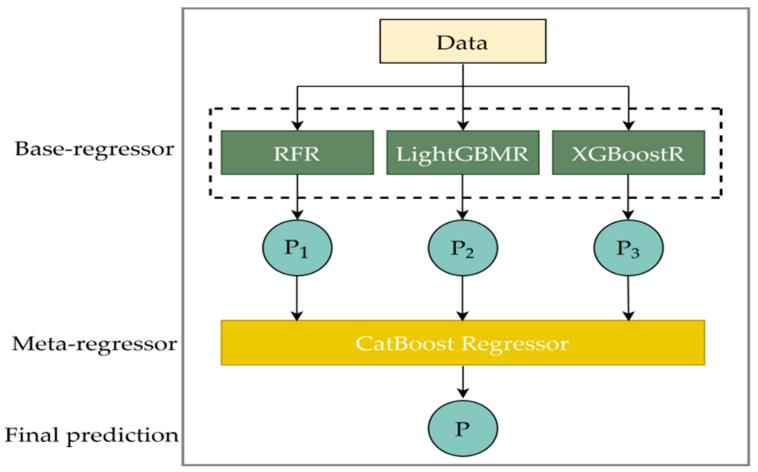
图5 用于茶多酚预测的stacking回归模型流程
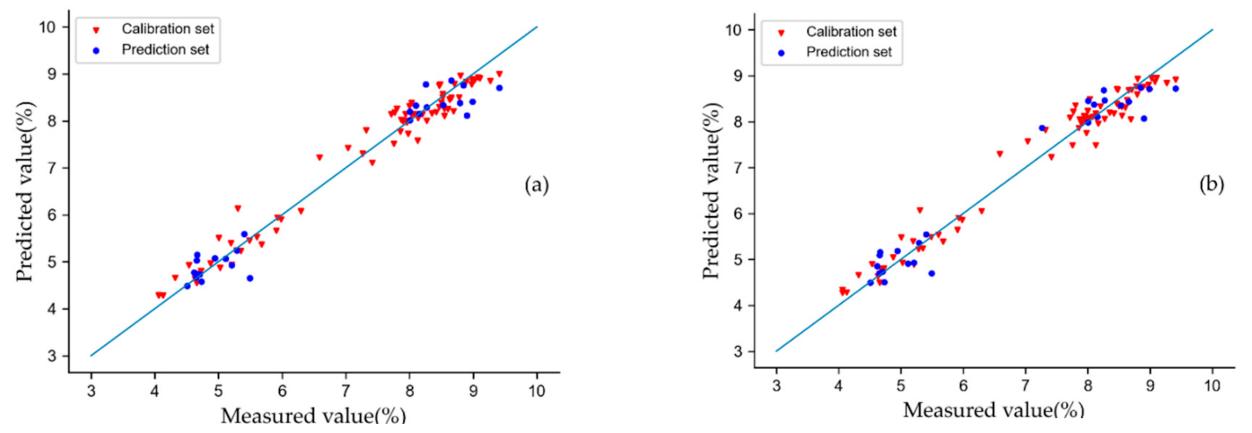
图6 基于CatBoost + stacking模型的茶多酚预测结果。更换样本前的预测结果(a)和更换样本后的预测结果(b)。
作者信息
康志亮,博士,四川农业大学机电学院教授,博士生导师。
主要研究方向:信号与信息处理、传感器与检测技术、自动控制。
Luo, X., Xu, L.j., Huang, P., Wang, Y.c., Liu, J., Hu, Y., Wang, P., & Kang, Z.l. (2021). Nondestructive Testing Model of Tea Polyphenols Based on Hyperspectral Technology Combined with Chemometric Methods. Agriculture, 11:673-687.
https://doi.org/10.3390/agriculture11070673
 地址:无锡市梁溪区南湖大道飞宏路58-1-108
地址:无锡市梁溪区南湖大道飞宏路58-1-108
.png) 电话:13810664973
电话:13810664973
.png) 邮箱:info@dualix.com.cn
邮箱:info@dualix.com.cn
地址:北京市海淀区中关村大街19号
电话:13810664973
邮箱:info@dualix.com.cn
地址:陕西省西安市高新区科技一路40号盛方科技园B座三层东区
电话:13810664973
邮箱:info@dualix.com.cn
地址:成都市青羊区顺城大街206号四川国际大厦七楼G座
电话:13810664973
邮箱:info@dualix.com.cn
地址:深圳市龙华区民治梅龙路电话:13810664973邮箱:info@dualix.com.cn
 在线咨询
在线咨询