
背景
番茄成熟度是描述番茄生长状态和品质的重要指标。成熟期中等的番茄保质期较长,适合保存,具有较高的商业价值。因此,准确区分中间成熟度有助于小农和小型食品加工企业进行收获和储存决策。高光谱成像技术作为一种高效、无损的技术,将传统光谱分析与机器视觉有机结合,在水果成熟度检测中得到了广泛应用。高光谱图像包含数百个连续波段的大量数据,可以提供丰富的番茄成熟度相关信息。因此本研究利用高光谱成像技术对番茄成熟度进行区分。
考虑到有监督方法中获取大量准确的成熟度标签是费时费力的,并且随着标记样本数量的增加,错误标签的可能性也会增加。无监督方法由于缺乏先验信息,模型的性能可能较差。而基于图的方法计算效率更高,泛化能力更好。此外,稀疏表示模型在图的构造上取得了很大的成功,它可以自动获取邻接关系和边权重值。因此,本研究采用基于图的方法结合稀疏表示来判别番茄成熟度。
试验设计
南京农业大学江亿平副教授团队利用搭载有400–1000 nm(Andors Zyla,Oxford)和1000–2500 nm(V10E,Specim)高光谱相机的高光谱分选仪(GaiaSorter,江苏双利合谱)(图1),获取了四个不同成熟阶段的番茄高光谱影像。后续对高光谱影像进行黑白板校正、ROI区域提取以及多重散射校正,以获得每个样本的平均光谱。
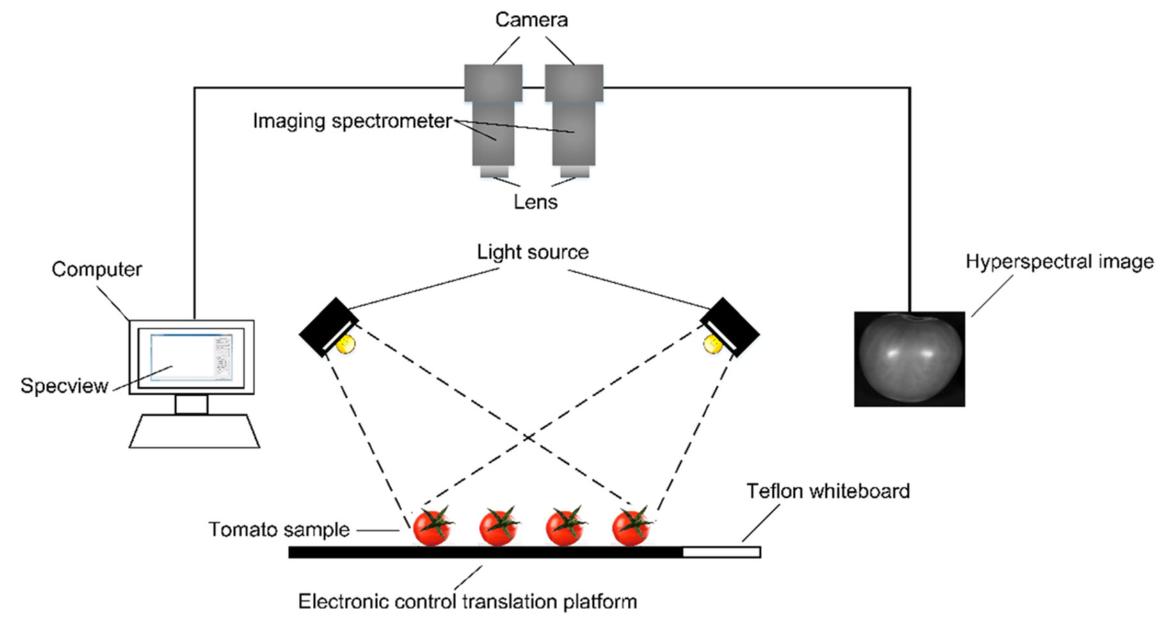
图1 用于番茄成熟度判别的高光谱成像系统
本研究设计了一种基于高光谱数据的半监督番茄成熟度判别方法。这种方法包括三个连续的步骤(图2)。首先,对标记样本进行稀疏编码,得到番茄样本的类概率信息;然后,设计了一种基于光谱信息散度和拉普拉斯分数(SIDLS)的半监督特征选择方法,其中利用类概率信息来构造图,以实现从原始波段集中选择有效特征子集;最后,建立基于类概率信息(CSR)的稀疏表示,构建反映样本之间关系的连接图,并利用标签传播算法区分未标记样本的成熟度标签。
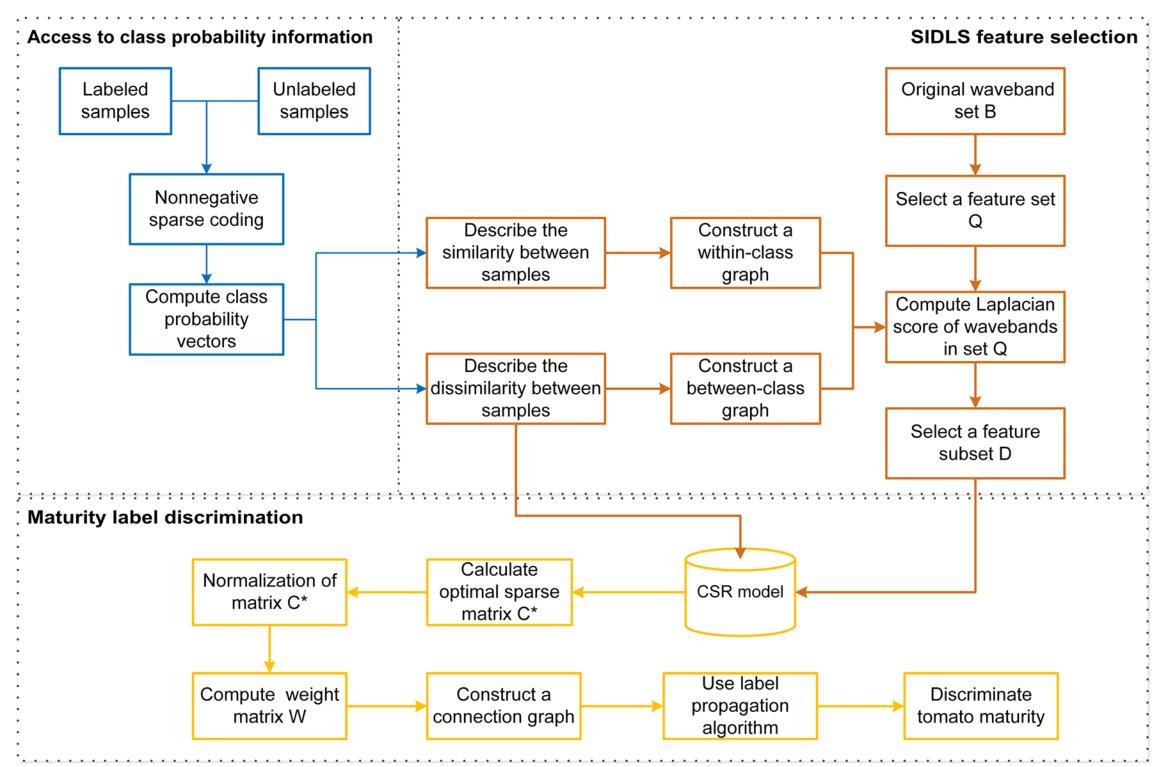
图2 考虑类别概率信息的基于图的半监督与稀疏表示相结合的番茄成熟度判别流程图
结论
为了验证CSR模型是否可以构建更具判别性的连接图,其他的图构造方法包括高斯核(GK)函数,局部线性嵌入(LLE),局部线性重建(LLR),以及稀疏表示模型(SR)在使用无特征选择和相同标签传播(LP)算法的情况下与CSR模型进行了比较。具体模型参数设置如表1所示。
表1 每种判别方法的*优参数

如图3所示,与SR模型和CSR模型相比,GK、LLR和LLE三种方法的性能都相对较差。这三种方法依赖于参数K,需要手动设置该参数,这可能会受到主观因素和高光谱数据噪声的影响。CSR模型和SR模型都能自动获得邻接关系和权重,受主观因素影响较小。此外,在标记样本数量相同的情况下,CSR模型对番茄成熟度判别的整体准确率高于SR模型。这表明,如果稀疏表示模型考虑了类信息,可能会有效提高学习性能。与SR模型相比,CSR模型在连接图的构建中利用了类概率信息。该模型输出的完整连接图能够反映番茄样本之间的真实关系。
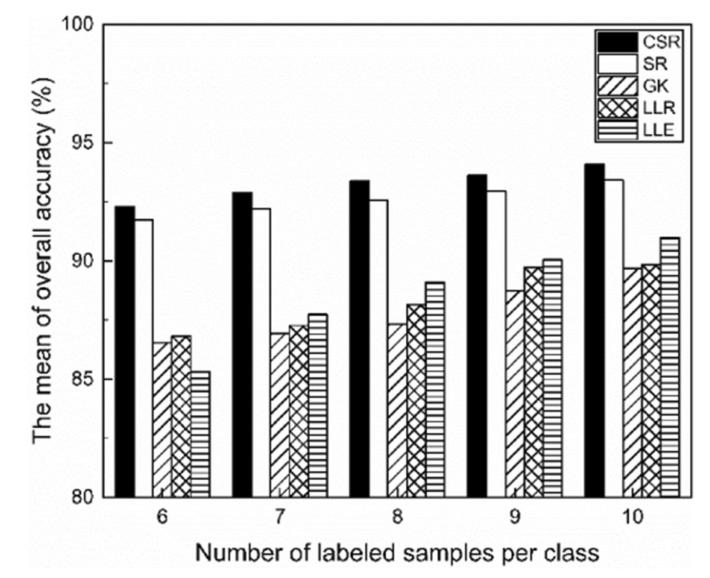
图3 CSR模型与其他无特征选择方法的精度比较
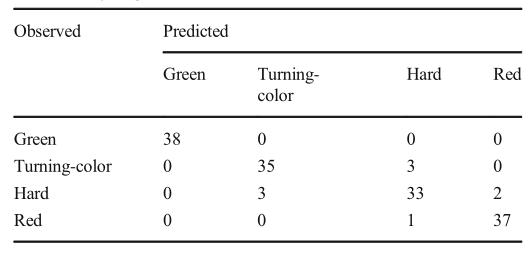
通过对比模型性能可以发现,CSR模型在各成熟度阶段的查全率、查准率和F1分均不低于其他图构造方法(表2)。虽然CSR和SR模型可以很好地区分番茄的绿色和红色成熟期,但是依然有大量错误判断集中在中期成熟阶段。原本属于变色期的番茄被误认为相邻的硬期。原本属于硬期的番茄被错误地判断为变色期和红期。但是获取大量的成熟度标签是非常困难和耗时的。为了克服这一缺点,有必要设计一种使用较少标记的番茄样品的鉴别方法。
表2 每个成熟度阶段有10个标记样本的CSR模型的混淆矩阵
为了验证SIDLS算法是否能够选择更有效的特征子集并减少特征选择中的信息损失,在选择波段数量相同的情况下,将SIDLS算法与基于拉普拉斯分数(SSLS)和半监督fisher分数(SFS)算法进行了比较(图4)。本试验中采用CSR模型对特征选择后的番茄成熟度进行判别。CSR模型有四种:全波段-CSR模型(full-CSR)、SSLS算法-CSR模型(SSLS-CSR)、SFS算法-CSR模型(SFS-CSR)和SIDLS算法-CSR模型(SIDLS-CSR)。
SIDLS-CSR的整体准确率高于full-CSR,说明波段的选择在一定程度上提高了番茄成熟度判别的性能。SIDLS算法选择的特征子集比SSLS算法和SFS算法选择的特征子集有性能上的优势。SSLS-CSR模型和SFS-CSR的整体精度甚至低于full-CSR,这是由于SSLS和SFS算的基本参数k对数据噪声敏感,会去除一些相关波段,在特征选择中造成大量信息损失,以及这两种算法会忽略特征之间的相关性,逐个评估特征所导致的。
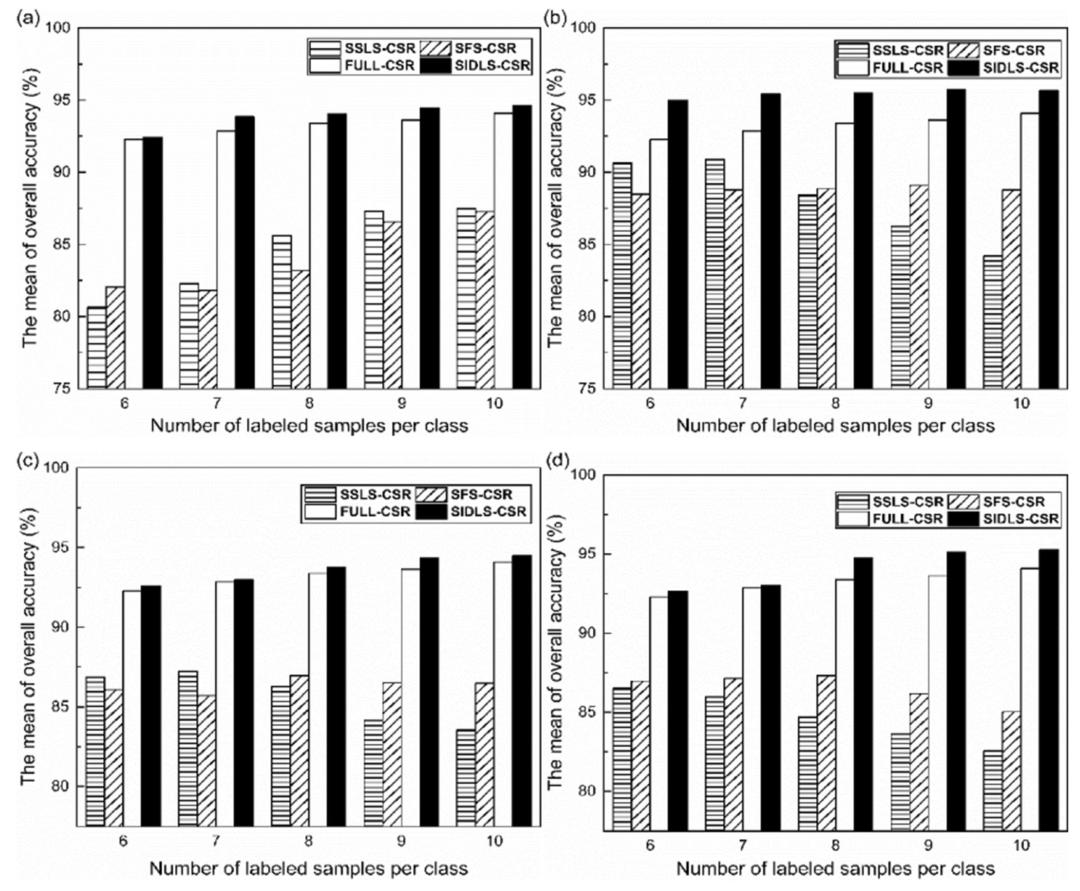
图4 基于不同特征选择算法的CSR模型比较。波段数分别为5(a)、10(b)、15(c)、20(d)
选择特征和标记样本的数量会影响SIDLS算法的性能。在特征选择后使用CSR模型进行实验,以测试模型性能随所选特征数量和标记样本数量的变化(图5)。当标记样本数量为10时,SIDLS算法的总体平均精度均有较大优势。当标记样本数量较少时,有用的先验信息会随着标记样本数量的增加而增加。当所选特征数为14个时,SIDLS算法在番茄成熟度判别上具有较大优势,总体准确率平均为96.78%。所选特征数较少时会导致重要信息的丢失,较多时则会包含冗余信息和噪声。
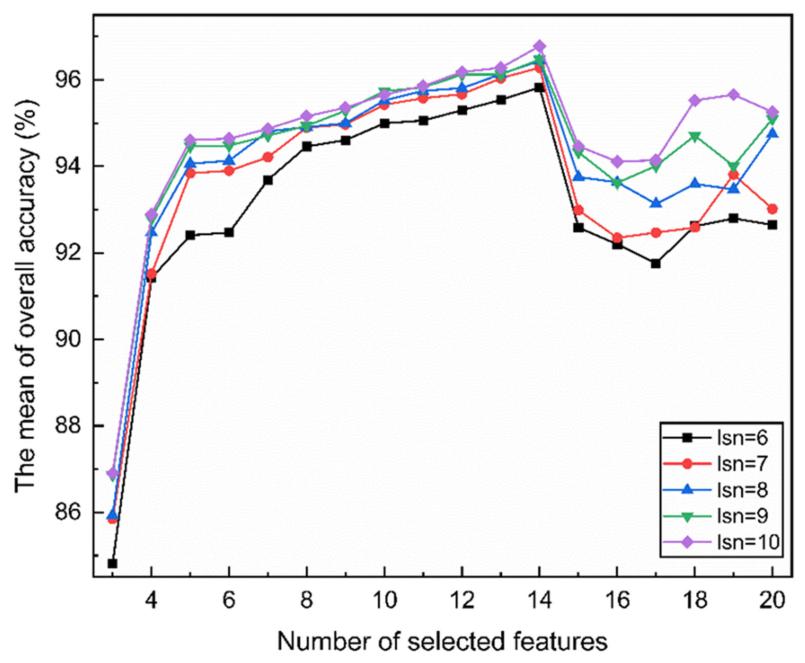
图5 SIDLS算法的性能随每类所选特征和标记样本数量的变化
综上所述,本研究提出了一种新颖可行的基于高光谱成像的方法,利用少量的标记样本来区分番茄的多个成熟度阶段。为了提高半监督学习的性能,该方法利用已知的标签信息描述番茄的类概率信息,并将其用于图的构造。在特征选择中,利用光谱信息散度和拉普拉斯分数选择相似度较低的特征子集,减少了高光谱数据的信息损失。在成熟度标签识别中,建立了基于类概率信息的稀疏表示模型,构建了更具鉴别性的连接图,提高了标签传播算法的性能。试验结果表明,该方法实现了番茄成熟度的无损准确判别,整体准确率可达96.78%,适用于小农和小规模食品加工企业。
作者信息
江亿平,博士,南京农业大学信息管理学院副教授,硕士生导师。
主要研究方向:农产品质量安全与智慧物流、数据驱动的系统优化与决策、农业大数据分析与信息技术、涉农电子商务与供应链管理等。
参考文献:
Jiang, Y.P., Chen, S.F., Bian, B., Li, Y.H., Sun, Y., & Wang, X.C. (2021). Discrimination of Tomato Maturity Using Hyperspectral Imaging Combined with Graph-Based Semi-supervised Method Considering Class Probability Information. Food Analytical Methods, 14, 968-983. https://link.springer.com/article/10.1007/s12161-020-01955-5
 地址:无锡市梁溪区南湖大道飞宏路58-1-108
地址:无锡市梁溪区南湖大道飞宏路58-1-108
.png) 电话:13810664973
电话:13810664973
.png) 邮箱:info@dualix.com.cn
邮箱:info@dualix.com.cn
地址:北京市海淀区中关村大街19号
电话:13810664973
邮箱:info@dualix.com.cn
地址:陕西省西安市高新区科技一路40号盛方科技园B座三层东区
电话:13810664973
邮箱:info@dualix.com.cn
地址:成都市青羊区顺城大街206号四川国际大厦七楼G座
电话:13810664973
邮箱:info@dualix.com.cn
地址:深圳市龙华区民治梅龙路电话:13810664973邮箱:info@dualix.com.cn
 在线咨询
在线咨询