
基于可见_近红外高光谱图像的药品快速鉴别研究
江苏双利合谱科技有限公司
0 前言
化橘红又名化皮、化州橘红,为芸香科植物化州柚的未成熟果实的外层果皮。前者习称“毛橘红”,后者习称“光七爪”、“光五爪”。化橘红不仅具有治咳化啖、健胃行气、醒酒功能,而还是人体美容的最佳原料,有广阔的市场前景。研究表明,挥发油,黄酮类化合物,多糖以及香豆素类化合物等是化橘红的主要有效成分。吴宋夏证实了化橘红中的黄酮苷具有镇痛、抗炎、解热的作用;香豆素类化合物具有抗氧化、抗菌抗病毒之功效。不同的品种有效成分的含量不一样,功效不一样,并且在价格上也相差较大,以正品皮的效果最佳。因此市场上存在许多用化橘红的正品果、伪品果、伪品皮冒充正品皮,损害了消费者利益,也冲击了种植优良品种的农民们的利益。
目前对正品皮常用的鉴别方法主要有性状鉴定、显微鉴定、高效液相色谱法。这些方法虽然各有优势,但是存在不同程度上的主观性强、需要预处理、实验过程复杂等缺点,不能满足市场快速、可靠检测的需要。本研究分别利用400-1000nm、1000-2500nm两款成像高光谱相机获取正品皮、伪品皮、正品果、伪品果四种化橘红成分的高光谱信息,利用光谱指数(DVI、NDVI)、偏最小二乘判别分析(PLS-DA)和极限学习法(ELM)三种方法分别构建四种不同成分的鉴别模型,并用独立样本数据对不同的模型进行验证。
1 材料与方法
1.1 材料
试验用的化橘红四种不同成分正品皮、伪品皮、正品果、伪品果由广东省食品药品职业技术学校提供,其中正品皮样本32个、正品果10个、伪品果11个,伪品皮7个。样本经粉碎均匀后,各取5g放置于培养皿上,标号,用于高光谱相机的光谱采集。
1.2 高光谱图像采集
高光谱图像数据采集采用江苏双利合谱科技有限公司的 GaiaSorter高光谱分选仪系统(V10E、N25E-SWIR)。该系统主要由高光谱成像仪、面阵列相机、卤素灯光源、暗箱、计算机组成,如图1。实验仪器参数设置如表1。

图1 GaiaSorter 高光谱分选仪
表1 GaiaSorter 高光谱分选仪系统参数
|
序号 |
相关参数 |
V10E |
N25E-SWIR |
|
1 |
光谱范围 |
400-1000 nm |
1000-2500 nm |
|
2 |
光谱分辨率 |
2.8 nm |
12 nm |
|
3 |
像面尺寸 |
6.15×14.2 |
7.6×14.2 |
|
4 |
倒线色散 |
97.5nm/mm |
208nm/mm |
|
5 |
相对孔径 |
F/2.4 |
F/2.0 |
|
6 |
杂散光 |
<0.5% |
<0.5% |
|
7 |
波段数 |
520 |
288 |
|
8 |
成像镜头 |
25 mm |
30 mm |
在进行高光谱图像采集时,需要设置相机曝光时间,平台移动速度以及物镜之间的距离。这 3 个参数相互影响,图像调节的目的是使采集的图像大小合适,清晰,不变形失真。经过反复尝试,物镜高度设置为 31 cm,曝光时间设置为10ms,平台移动速度分别设置为 6.0 mm/s(400-1000 nm)、16mm/s(1000-2500 nm)。图像采集软件采用江苏双利合谱科技有限公司提供的高光谱成像系统采集软件完成。图像处理采用 ENVI5.3 软件进行处理。在进行图像处理之前,先要对采集的光谱图像进行图像校正,图像校正公式如下:
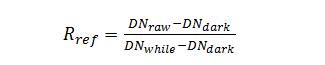
式中,Rref 是校正过的图像,DNraw 是原始图像,DNwhite为白板校正图像,DNdark 是黑板校正图像。高光谱图像的光谱与图像之间有着对应的关系,据此,在正品皮、伪品皮、正品果、伪品果四种样本上选取 25×25 像素点的感兴趣区域,以感兴趣区域所有像素的光谱平均值作为该样本的平均光谱。
1.3 光谱噪声去除
试验得到光谱含有由仪器和试验条件等引起的噪声,对这些噪声的处理有助于减少噪声对光谱分析的影响,突出光谱的有效信息。SG 平滑算法可以有效消减光谱数据中的随机噪声,消噪效果受平滑点数的影响,本文中选择SG 二次多项式 7 点平滑对光谱数据进行处理(何勇,2013)。
1.4 特征波长选择
光谱信息之间存在大量的冗余和共线性信息特征,对光谱有效信息的提取产生了较大的干扰,且大量光谱数据造成模型复杂、计算量大的问题。本文采用连续投影算法(successive projections algorithm,SPA)进行特征波长的选择,以减少信息冗余和共线性的影响,简化模型,减少计算量。
SPA 是一种特征变量前向选择算法,在光谱特征波长中取得了广泛的应用。本文采用 SPA 算法对去噪处理后的光谱进行特征波长选择。进行SPA 计算时,以建模集的光谱数据和类别赋值为输入,设置选择特征波长数的范围为 5~30。
1.5 光谱指数
光谱指数的产生来源于植被指数,植被指数是指利用卫星不同波段探测数据组合而成的,能反映植物生长状况的指数。植物叶面在可见光红光波段有很强的吸收特性,在近红外波段有很强的反射特性,这是植被遥感监测利用卫星不同波段探测数据组合而成的,能反映植物生长状况的指数。植物叶面在可见光红光波段有很强的吸收特性,在近红外波段有很强的反射特性,这是植被遥感监测的物理基础,通过这两个波段测值的不同组合可得到不同的植被指数。光谱指数是通过任意两波段组合或三波段组合成各种光谱指数,如NDVI、DVI等,探寻最佳的波段组合用于各个领域的模型构建等。
归一化植被指数(Normalized difference vegetable index)
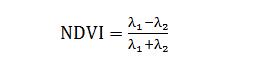 (2)
(2)
差值植被指数(Difference vegetable index)
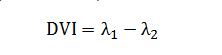 (3)
(3)
其中,λ1和λ2代表任意波长的反射率,波段范围为400-1000 nm与1000-2500 nm。
1.6 判别分析方法
偏最小二乘法判别分析(PLS-DA ,Partial least squares discrimination analysis)是一种用于判别分析的多变量统计分析方法。判别分析是一种根据观察或测量到的若干变量值,来判断研究对象如何分类的常用统计分析方法。其原理是对不同处理样本(如观测样本、对照样本)的特性分别进行训练,产生训练集,并检验训练集的可信度(Luna et al., 2013)。本文分别基于全光谱、特别波长光谱建立 PLS-DA 判别分析模型,通过建立光谱数据与类别特征之间的回归模型,进行判别分析。
1.7 极限学习机
极限学习机(extreme learning machine)ELM是一种简单易用、有效的单隐层前馈神经网络SLFNs学习算法。2004年由南洋理工大学黄广斌副教授提出。传统的神经网络学习算法(如BP算法)需要人为设置大量的网络训练参数,并且很容易产生局部最优解。极限学习机只需要设置网络的隐层节点个数,在算法执行过程中不需要调整网络的输入权值以及隐元的偏置,并且产生唯一的最优解,因此具有学习速度快且泛化性能好的优点。本文中隐含层神经元个数从 1 到 520(288)以步长 1 进行寻优,以最小训练误差下的神经元个数为 ELM 模型隐含层神经元个数。
1.8 评价指标
回归模型得到的样本的预测值不是整数,需要设置阈值以判断样本的归属。本文中阈值设置为 0.5 ,预测值小数点大于或等于0.5则加1归整,小于0.5则减1归整。总体识别精度是指正确识别的个数除以总数,正品皮识别精度是指正品皮正确识别的个数除以正品皮的总数,正品皮识别错误率指数被错误分为正品皮的个数除以正品皮的总数。
2 结果与分析
2.1 化橘红不同成分的原始光谱曲线
本试验采用的V10E 相机获取的是400-1000 nm波长范围共520个波段的可见/近红外光谱数据,N25E-SWIR相机获取的是1000-2500 nm波长范围共288个波段的近红外光谱数据,全部样本的原始光谱图如图 2所示,正品皮、伪品皮、正品果、伪品果的光谱比较图如图3所示。
从图2和图3可以看到,总体而言,无论是400-1000 nm或1000-2500 nm波长范围内,正品皮的光谱反射率值低于其他三种成分的光谱曲线,从曲线变化趋势来看四种不同成分并没有十分明显的差异。本研究按照Kennard-Stone 算法将样本分成建模集和预测集,其中建模集 38 个样本,预测集32个样本。正品皮、伪品皮、正品果、伪品果分别赋值为 1、2、3、4(表 2),不同化橘红成分建模集和预测集样本的划分如表 2所示。
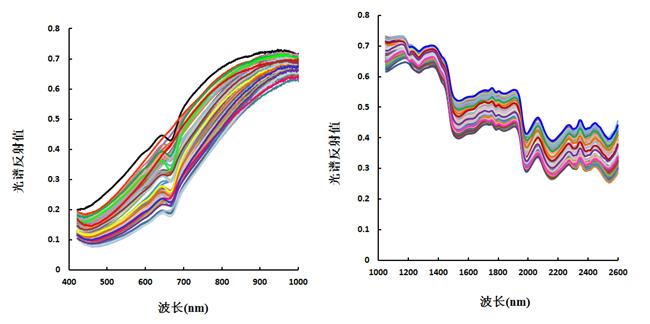
图2 全部化橘红样本的原始反射光谱图
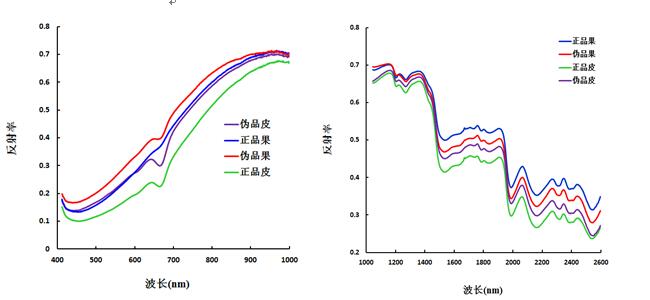
图3 化橘红不同成分反射光谱曲线图
表2 化橘红不同成分类别赋值与建模集合检验集样本划分
|
|
正品皮 |
伪品皮 |
正品果 |
伪品果 |
|
类别赋值 |
1 |
2 |
3 |
4 |
|
建模集 |
22 |
4 |
5 |
7 |
|
检验集 |
20 |
3 |
5 |
4 |
2.2 主成分分析定性分析
对化橘红的四种不同成分的光谱数据进行主成分分析(principal component analysis,PCA) 可知,400-1000 nm范围内,第一主成分(principle component 1, PC1)的贡献率为88.36%,PC2 的贡献率为7.24%,PC1 和 PC2 累计贡献率为95.6%,PC1 和 PC2 能够解释绝大部分的变量;在1000-2500 nm范围内,第一主成分(principle component 1, PC1)的贡献率为93.27%,PC2 的贡献率为3.72%,PC1 和 PC2 累计贡献率为97.0%,PC1 和 PC2 也能够解释绝大部分的变量;图4分别为400-1000 nm与1000-2500 nm范围内,第一主成分与第二主成分的散点分布图。
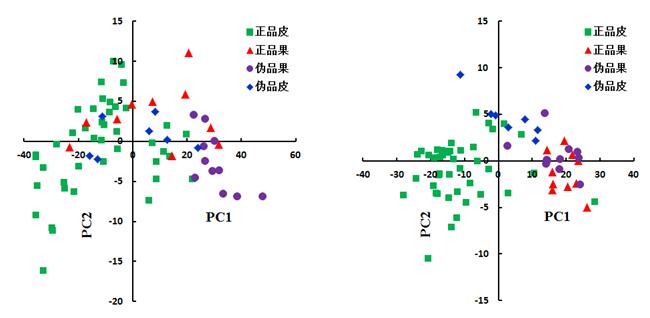
图4 400-1000nm(左)、1000-2500nm(右)第一主成分与第二主成分的得分散点分布图
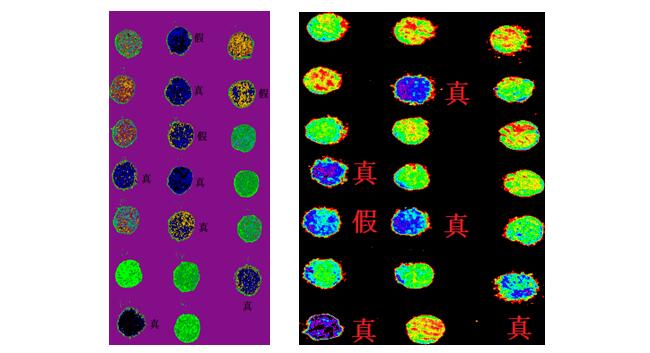
图5 主成分组合识别正品皮(左:400-1000 nm,右:1000-2500 nm)
由图 4 可知,在400-1000 nm与1000-2500 nm范围内,各不同成分之间较难直接区分出来,得分图中均有重合的地方。从图5亦可以看出无论是400-1000 nm或1000-2500 nm,主成分的成分组合均未能完全从正品皮、伪品皮、正品果、伪品果四种样本中识别出正品皮,从图5可知,识别出的正品皮亦有假的正品皮。因此需要对光谱数据进行进一步的分析和处理,以鉴别化橘红不同成分。
2.3 光谱指数
本研究使用的成像高光谱仪V10E范围是400-1000nm,N25E-SWIR范围是1000-2500 nm,通过不同波段的重新组合,形成不同形式的光谱指数(归一化光谱指数,NDVI;差值光谱指数,DSI)。
运用Matlab软件编程,将两两组合的所有波段构建的光谱指数与各类别赋值,计算相应的决定系数(R²),绘制决定系数图。图中颜色从蓝色到红色变化,图像颜色越红,表示决定系数越大,图像颜色越蓝,表示决定系数越小。图6为化橘红各成分分类赋值与NDVI、DVI决定系数(R2)二维图。从图6可知,在400-1000 nm范围内, DVI模型决定系数最高的两波段在绿光范围内,分别是538.91 nm和543.75nm;NDVI模型绝对系数最高的两波段989.76 nm和670.39 nm。在1000-2500 nm范围内,NDVI和DVI两个光谱指数模型决定系数最高的两波段组合均为是1820.72 nm和1787.12 nm。综合400-1000 nm与1000-2500 nm
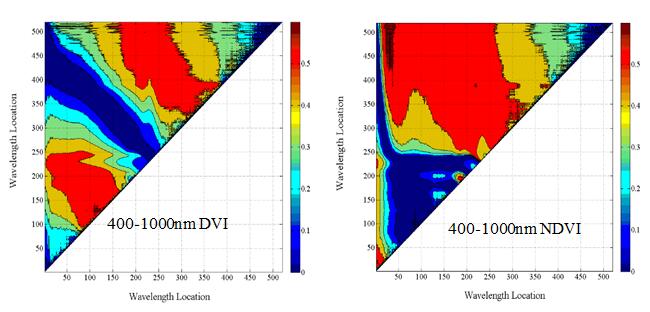
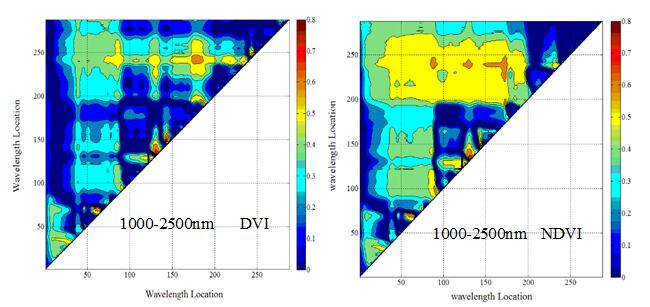
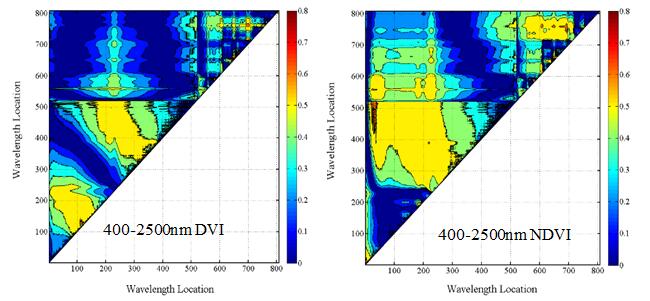
图 6化橘红各成分分类赋值与NDVI、DVI决定系数(R2)二维图
两组数据构建NDVI和DVI模型时,NDVI和DVI两个光谱指数模型决定系数最高的两波段组合与1000-2500 nm范围内相同。比较400-1000 nm和1000-2500 nm的决定系数图可知,在1000-2500 nm范围内,NDVI与DVI构建的模型决定系数较高。
根据图6可知,在400-1000 nm范围内,DVI(538.91/543.75)与NDVI(989.76/670.39)与类别赋值构建的模型决定系数最高,分别为0.643和0.640。在1000-2500 nm范围内,DVI(1820.72 /1787.12)与NDVI(1820.72 /1787.12)与类别赋值构建的模型决定系数最高,分别为0.861和0.834。图7分别为DVI(538.91/543.75)、NDVI(989.76/670.39) 、DVI(1820.72 /1787.12)、NDVI(1820.72 /1787.12)与类别赋值的线性拟合散点分布图,从图中可知,在1000-2500 nm范围内构建的NDVI、DVI光谱指数与类别赋值拟合度最高,且变化曲线显著。
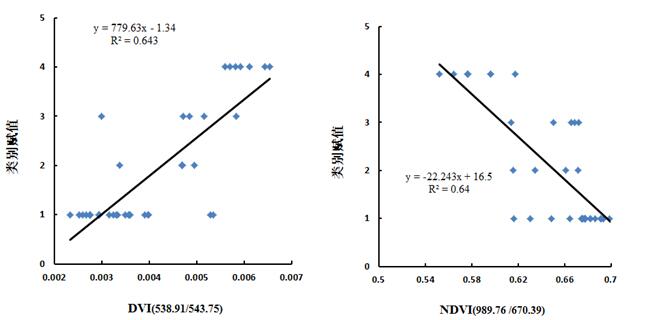
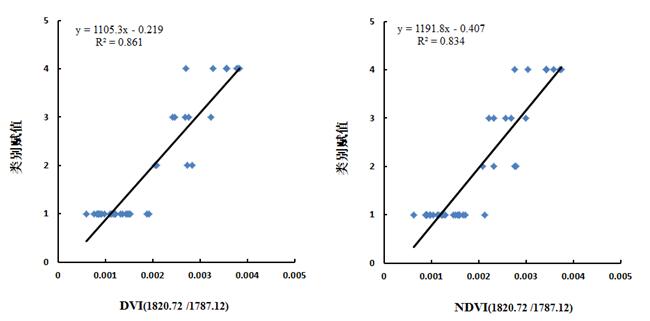
图7 DVI、NDVI光谱指数与类别赋值的散点分布图
运用独立的数据,分别对图7中DVI(538.91/543.75)、NDVI(989.76/670.39) 、DVI(1820.72 /1787.12)、NDVI(1820.72 /1787.12)与类别赋值构建的模型进行检验,检验结果如图8和表3所示。根据查表可知,1-15与28-32为正品皮,15-25号为16-20正品果、21-24为伪品果,25-27为伪品皮。从图8可知,正品皮、正品果、伪品果、伪品皮之间均存在不同程度的错误识别。表3基于DVI、NDVI光谱指数模型检验化橘红样本的精度评价表。表中分别统计了总体识别精度、正品皮识别精度和正品皮识别错误率。从表3中可知,总体识别精度、正品皮识别精度最高的均为DVI(1820.72 /1787.12)构建的模型,分别是66%和75%,正品皮识别错误率最低的则为DVI(1820.72 /1787.12)、NDVI(1820.72 /1787.12) 构建的模型,均为5%。
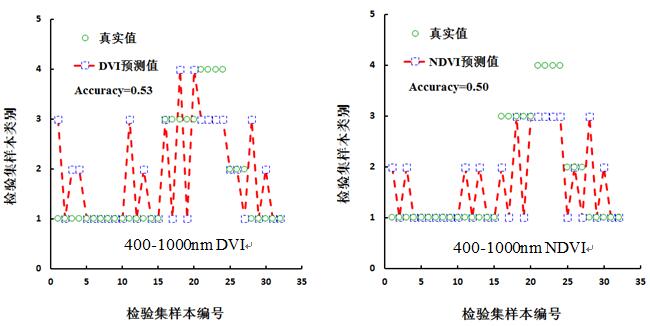
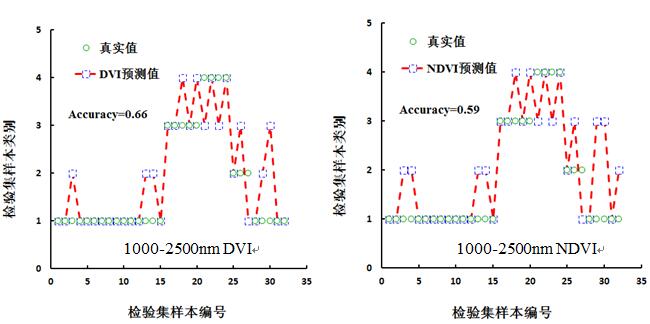
图 8 基于NDVI、DVI检验集预测结果对比图
表2 基于光谱指数模型检验化橘红样本的精度评价
|
|
总体识别精度% |
正品皮识别精度% |
正品皮识别错误率% |
|
400-1000 (DVI) |
53 |
65 |
15 |
|
400-1000 (NDVI) |
50 |
70 |
20 |
|
1000-2500 (DVI) |
66 |
75 |
5 |
|
1000-2500 (NDVI) |
59 |
65 |
5 |
本文以建模集样本的光谱数据和类别赋值为输入,利用连续投影算法SPA选择特征波长。选出的特征波长的个数如表 3所示。从表 3 可知,400-1000 nm范围内所选择的特征波段为15个,1000-2500 nm范围内所选择的特征波段较少,为5个。
表 3在400-1000 nm与1000-2500 nm范围内SPA 算法选择的特征波长个数
|
范围 |
波段位置/nm |
|
400-1000 nm |
395.23, 396.40, 399.90, 401.06, 422.13, 501.59, 670.39, 735.79, 743.39, 872.13, 940.31, 962.16, 974.58, 981.45, 992.73 |
|
1000-2500 nm |
1461.59, 1714.23, 2038.97, 2329.25, 2574.24 |
2.5 偏最小二乘判别分析
分别将建模集合检验集的全波段光谱及特征波段光谱作为偏最小二乘法判别分析输入变量,从而获取预测样本类别的赋值。图9为检验集与预测值的类别赋值图,并针对图9进行总体识别精度、正品皮识别精度、正品皮识别错误率的统计,如表4所示。从表4中可知,总体识别精度、正品皮识别精度最高的均为在1000-2500 nm范围内的PLS-DA构建的模型,分别是78%和90%,正品皮识别错误率最低的则为1000-2500 nm范围内的PLS-DA、PLS-DA 构建的模型,均为5%。从表4可以看出,无论是400-1000 nm或1000-2500 nm,基于全波段的PLS-DA模型总体识别率和正品皮识别率均高于基于特征波段的PLS-DA模型,而正品皮的错误识别率,无论是400-1000 nm或1000-2500 nm范围内,基于全波段的PLS-DA模型与基于特征波长的PLS-DA模型的错误识别率相同,400- 1000 nm范围错误识别率均为10%,1000-2500范围错误识别率则为5%。
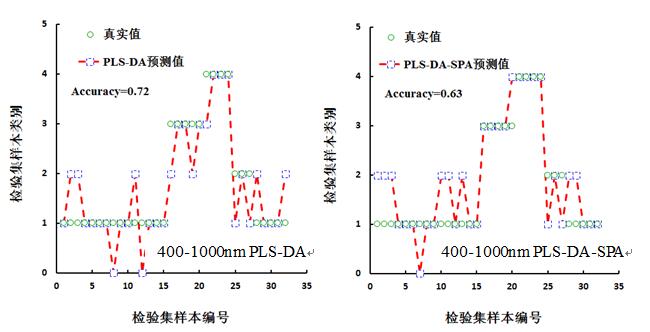
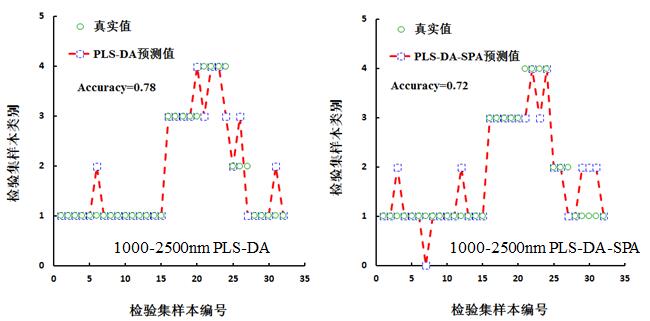
表4基于PLS-DA模型检验化橘红样本的精度评价
|
|
总体识别精度% |
正品皮识别精度% |
正品皮识别错误率% |
|
400-1000 (PLS-DA) |
72 |
65 |
10 |
|
400-1000 (PLS-DA-SPA) |
63 |
55 |
10 |
|
1000-2500 (PLS-DA) |
78 |
90 |
5 |
|
1000-2500 (PLS-DA-SPA) |
72 |
70 |
5 |
分别将建模集合检验集的全波段光谱及特征波长光谱作为极限学习机的输入变量,从而获取预测样本类别的赋值。图10为检验集与预测值的类别赋值图,并针对图10进行总体识别精度、正品皮识别精度、 正品皮识别错误率的统计,如表5所示。从表5中可知,总体识别精度、正品皮识别精度最高的均为在1000-2500 nm范围内的ELM与ELM-SPA构建的模型,分别是84%和95%,正品皮识别错误率最低的则为1000-2500 nm范围内的ELM与ELM-SPA 构建的模型,均为5%。从表5可知,在400-1000 nm范围内,基于特征波段光谱的ELM模型总体识别率与正品皮识别率均高于基于全波段的ELM模型,对于正品皮的识别错误率,基于全波段与基于特征波段的错误识别率相同;在1000-2500 nm范围内,无论是基于全波段光谱或基于特征波段的ELM模型,其总体识别率、正品皮识别率、正品皮识别错误率均相同,分别为84%、95%和5%。
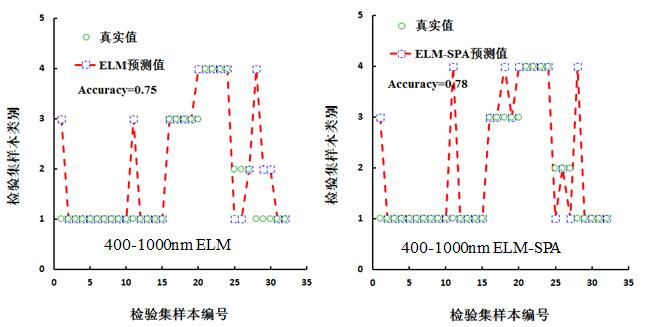
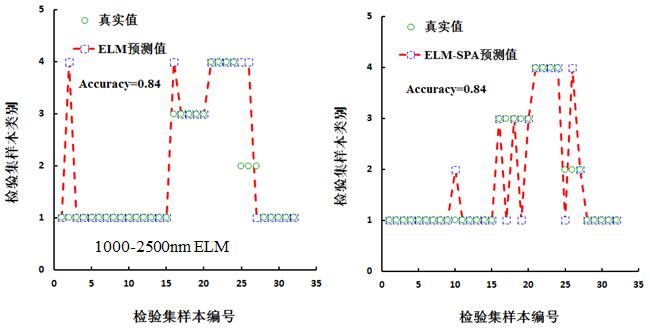
图 10 基于ELM检验集预测结果对比图
表4 基于ELM模型检验化橘红样本的精度评价
|
|
总体识别精度% |
正品皮识别精度% |
正品皮识别错误率% |
|
400-1000 (ELM) |
75 |
75 |
10 |
|
400-1000 (ELM-SPA) |
78 |
85 |
10 |
|
1000-2500 (ELM) |
84 |
95 |
5 |
|
1000-2500 (ELM-SPA) |
84 |
95 |
5 |
2.7 光谱指数模型,PLS-DA 模型,和 ELM 模型的比较
综合对比光谱指数模型,PLS-DA 模型,和 ELM 模型的识别效果可知,无论是光谱指数模型,PLS-DA 模型或ELM 模型,基于1000-2500 nm范围内构建的模型,其预测值的总体识别率、正品皮识别率均高于400-1000 nm范围内的模型,且正品皮的识别错误率也低于400-1000nm范围内的模型。在光谱指数模型、PLS-DA 模型和 ELM 模型的模型中,ELM 模型的识别准确性最高,其次是PLS-DA模型,最后是光谱指数模型。基于特征波段光谱的PLS-DA模型其识别准确性低于基于全波段光谱的PLS-DA的模型,但是基于特征波段光谱的ELM模型在400-1000 nm范围内,其识别准确性高于基于全波段光谱的ELM模型,在1000-25000 nm范围内,其识别准确性与基于全波段光谱的ELM模型相同。
3 结论与讨论
基于V10E与N25E-SWIR两款成像高光谱相机,分别获取正品皮、正品果、伪品皮、伪品果四种化橘红成分400-1000 nm与1000-2500 nm范围的光谱反射率,采用 SG 平滑算法对提取出的光谱数据进行去噪处理,同时采用 SPA 算法对去噪后的光谱提取特征波长,并分别基于全波段光谱、特征波段光谱建立 PLS-DA 判别模型和 ELM 模型,同时采用全波段循环,探寻最佳的NDVI、DVI两个光谱指数构建判别模型,用于鉴别正品皮、正品果、伪品皮、伪品果,取得了比较好的识别效果。基于特征波段光谱与全波段光谱建立的 ELM 模型取得了最佳效果,总体识别精度、正品皮识别精度、正品皮识别错误率分别为84%、95%和5%。在实际运用中,考虑到识别时间与成分,基于SPA算法提取的特征波段构建的ELM模型效果最佳。本论文研究结果为高光谱成像技术在药品真伪等检测中的应用提供了可行性。
 地址:无锡市梁溪区南湖大道飞宏路58-1-108
地址:无锡市梁溪区南湖大道飞宏路58-1-108
.png) 电话:13810664973
电话:13810664973
.png) 邮箱:info@dualix.com.cn
邮箱:info@dualix.com.cn
地址:北京市海淀区中关村大街19号
电话:13810664973
邮箱:info@dualix.com.cn
地址:陕西省西安市高新区科技一路40号盛方科技园B座三层东区
电话:13810664973
邮箱:info@dualix.com.cn
地址:成都市青羊区顺城大街206号四川国际大厦七楼G座
电话:13810664973
邮箱:info@dualix.com.cn
地址:深圳市龙华区民治梅龙路电话:13810664973邮箱:info@dualix.com.cn
 在线咨询
在线咨询