
红花籽油因其富含亚油酸等不饱和脂肪酸而具有较高的营养价值和市场价格,广泛应用于食品、医药及保健品领域。然而,由于其价格较高,在商业流通中常被掺杂廉价植物油(如玉米油、大豆油和葵花籽油),导致食品掺假问题频发,严重威胁消费者权益与食品安全。传统的掺假检测方法如气相色谱-质谱联用(GC-MS)虽然准确性高,但检测过程通常需要复杂的样品前处理、专*操作人员和昂贵设备,难以实现快速、高通量筛查。
高光谱成像技术(HSI)作为一种融合图像与光谱信息的无损检测手段,在农产品质量、安全性检测方面表现出良好应用前景。因此,开发一种结合GC-MS与HSI的高*检测方法,以实现对红花籽油掺假的快速识别和掺假水平的精准预测,具有重要的现实意义和应用价值。
作者信息:许丽佳,四川农业大学机电工程学院,博士生导师
期刊来源:Journal of Food Composition and Analysis
建立一种结合GC-MS与HSI的联合方法,用于快速、无损识别红花籽油(SSO)中是否掺假及掺假水平的定量预测,以提升植物油品质控制与掺假检测的准确性与效率。在研究方法上,作者首先制备不同掺假比例的红花籽油样本,掺假对象包括玉米油、大豆油和葵花籽油三种常见植物油。同时,使用高光谱成像系统采集样品在400–1000 nm波段范围内的图像数据,并提取反射率光谱特征。为了提升建模效率与准确性,研究引入多种光谱预处理方法,最终选用中值滤波(MF)处理高光谱数据,以显著降低噪声并提高模型的鲁棒性和泛化能力,在特征波段选择方面,识别出440 nm、530 nm 以及 880–950 nm 附近的波段更适合用于建立 SSO 掺假浓度的预测模型,同时也能缩短建模时间。模型构建方面,采用以岭回归(Ridge) 和偏最小二乘回归(PLSR)为基础模型、LightGBM为元模型的 Stacking 集成学习模型,实现了对 SSO 掺假浓度的高精度预测。在此基础上,进一步将 GC-MS 检测得到的亚油酸(LA)、油酸(OA)和棕榈酸(PA)含量与高光谱数据共同建模,使模型表现出卓越的预测性能。
采用不同比例将葵花籽油、大豆油和玉米油与不同体积的红花籽油的混合。在混合之前,纯油样先进行均质化处理。本研究共准备并分析了350个样品,包括50份纯油样和300份掺假油样。在光谱分析之前,使用漩涡混合器将油品混合均匀,并将其储存在4℃的黑暗环境中,以备进一步分析。
图1展示了本研究的整体流程。利用高光谱仪(图1a)采集油样的光谱数据,并通过气相色谱-质谱联用(GC-MS)技术(图1b)检测油样中亚油酸(LA)、油酸(OA)和棕榈酸(PA)的含量及浓度。
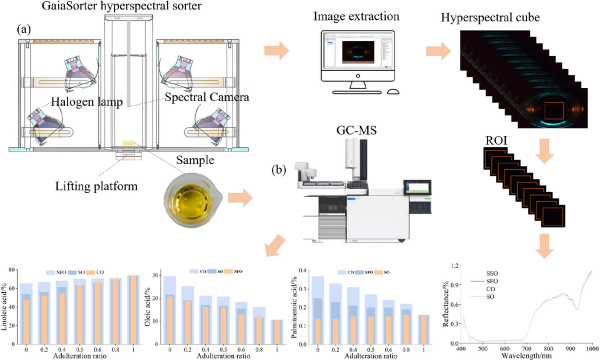
图1. 研究整体流程概览。
本研究的高光谱数据由江苏双利合谱科技有限公司生产的GaiaSorter高光谱成像仪进行采集,该系统的核心部件包括高光谱相机、光源、电动载物台、计算机、有效光谱范围为400-1000 nm,光谱分辨率为2.8 nm,共有256个波段,高光谱相机透镜与油样装载平台的距离设定为160 mm,电动载物台速度为4.6 mm/s,高光谱相机的曝光时间为8.5 ms。每个油样的光谱图像被单独收集,每个油样的三次扫描用于计算平均光谱。总共扫描了350个样品,得到89600个光谱数据值,并使用Specview软件进行了黑白标定。
有效的预处理可以消*环境因素和光谱设备本身非品质信息对高光谱数据的影响,为提高黑白白色校正后光谱数据的信噪比,采用了3种光谱预处理方法,即L2范数归一化(L2 NN)、乘性散射校正(MSC)、中值滤波(MF)。
本研究构建了岭回归(Ridge)、LightGBM、随机森林(RF)、梯度提升决策树(GBDT)、CatBoost、偏最小二乘回归(PLSR)和Stacking回归模型。其中Stacking是一种“集成学习”方法,如图2a所示。它将多个基础模型的预测结果输入一个元模型中进行再学习。将全部数据划分为训练集D_train和测试集D_test,D_train 又进一步划分为训练折叠和验证折叠。基础学习器在训练折叠上训练,并在验证折叠上输出预测结果,之后这些结果被送入次级学习器,用于学习各基础模型的权重。最终模型通过 N 层叠加学习器完成迭代学习并输出预测结果。
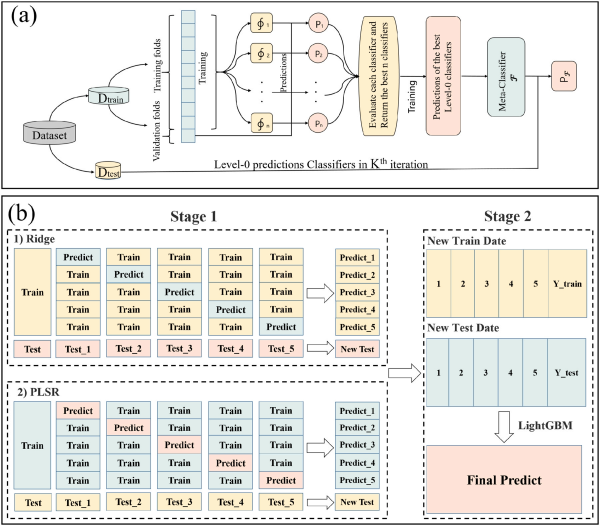
图2. 集成学习模型算法原理示意图 (a) "集成学习"方法迭代过程示意图 (b) 由Ridge、PLSR和LightGBM构成的多层学习系统
采用决定系数(R2)、均方根误差(RMSE)和拟合时间回归模型的评价标准。采用5折交叉验证法对模型进行检验。
图3展示了不同掺假浓度下混合油样的脂肪酸含量和平均光谱曲线。从图3(a-c)可以看出,亚油酸(LA)、油酸(OA)和棕榈酸(PA)的含量存在明显差异。葵花籽油和大豆油在脂肪酸组成上总体相似,但在棕榈酸含量上存在一定差距。同时,红花籽油(SSO)富含亚油酸。在光谱数据处理方面,移除了400 nm之前和1000 nm之后的严重干扰波段,主要分析400–1000nm范围内的光谱数据。图3(d-f)展示了使用高光谱成像仪采集的所有混合油样的平均光谱。红花籽油(SSO)与其他三种食用油在不同掺假浓度下展现出不同的光谱强度反射变化。
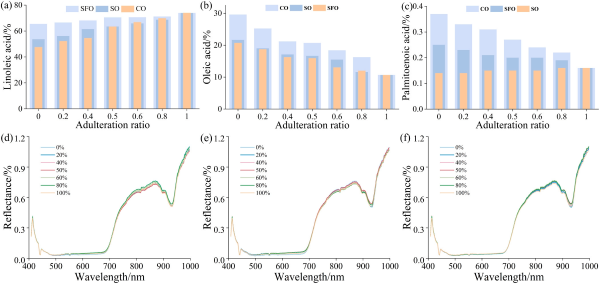
图3. 不同掺伪浓度混合油样的脂肪酸含量与光谱曲线 (a)-(c) 分别表示不同掺伪浓度下油样的亚油酸(LA)、油酸(OA)和棕榈酸(PA)含量变化;(d)-(f) 分别展示不同掺伪比例下红花籽油(SFO)、大豆油(SO)和玉米油(CO)的光谱曲线特征。
在回归分析中,将样品的光谱曲线数据按0.75:1的比例分为训练集与测试集。基于LightGBM算法对于不同方法预处理后的数据进行建模。在各种预处理方法中,MF预处理的效果*好,在测试集上的R2为0.857,RMSE为0.106,在交叉验证中,R2 cv = 0.815,RMSEcv = 0.111。MF的应用有利于数据的平滑处理,对后续的分析有积极的影响。
之后实验中使用了Ridge、LightGBM、CatBoost、RF、GBDT、PLSR算法以及Stacking模型对MF预处理过的光谱进行建模处理。使用全波段信息建模时可以发现,CatBoost、RF和GBDT三种模型的决定系数 R² 及其交叉验证值 R²cv 均低于 0.8,不适合进行后续回归分析。而 Ridge 回归、LightGBM 和 PLSR 三种算法的 R² 与 R²cv 均高于 0.8,适用于后续的回归建模。其中,Ridge 模型在单一模型的测试集中表现*好,其 R²达到 0.930,交叉验证 R²cv 为 0.852,且建模耗时较短。本研究中,Stacking 模型以 Ridge 和 PLSR 为基础模型,LightGBM 为元模型。Stacking 模型在测试集上的 R² 提升至 0.943,RMSE 降至 0.066;其交叉验证性能也更加理想,R²cv 达到 0.881,RMSEcv 为 0.089。与单一模型如 Ridge 相比,Stacking 模型充分融合了三种模型的优势,在各项性能指标上均实现了显著提升。采用 MF 预处理算法后所建立的模型,有效增强了四种算法的预测性能。Ridge、LightGBM、PLSR 及 Stacking 模型在红花籽油掺假预测中的结果见图 4。
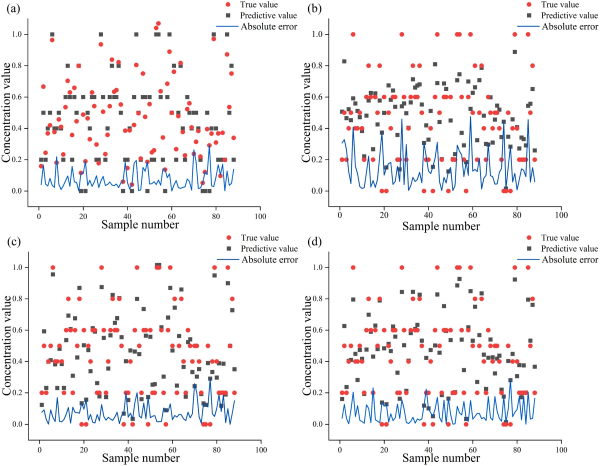
图4. 基于MF预处理的不同算法模型建模结果对比 (a)岭回归(Ridge)模型建模结果 (b)轻量梯度提升机(LightGBM)建模结果 (c)偏最小二乘回归(PLSR)建模结果 (d)Stacking集成模型建模结果
为了降低建模过程中的复杂度,实现高*检测,采用了特征波段建模方法,本研究选择 Ridge 回归模型作为特征提取工具,用于提取具有权重的前30个特征波段,其在光谱中的分布如图 5a 所示。所选波段主要集中在 440 nm、530 nm 以及 880–950 nm 附近。之后研究使用这些筛选出的波段进行建模分析。实验结果表明,MF-Ridge-Stacking模型的建模性能优于MF-LightGBM、MF-CatBoost、MF-RF、MF-GBDT、MF-PLSR、MF-Ridge和MF-Stacking模型, MF-Ridge-Stacking回归分析模型的R2 cv为0.913,RMSE cv为0.076,R2为0.944,RMSE为0.065,表明了基于特征波段的掺假浓度回归分析的优越性。
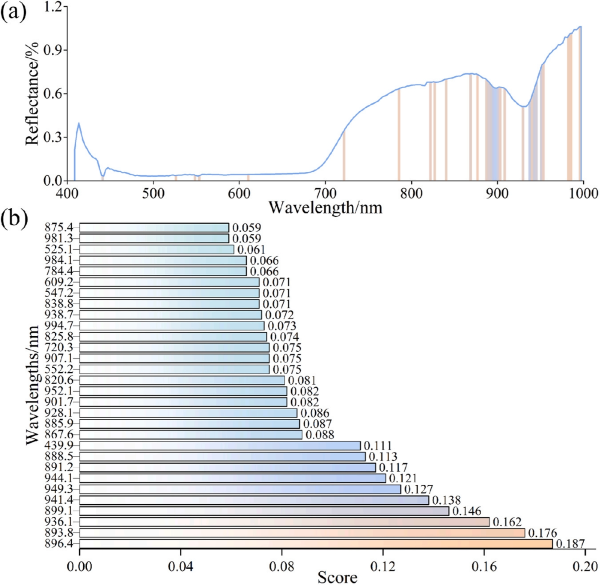
图5. 岭回归特征提取结果可视化(a) 岭回归算法筛选的特征波长分布图(b) 前30个特征波长得分排序图
为了深入分析每个特征与每种脂肪酸含量之间的关系,整合了不同掺假浓度油样的数据,并进一步探讨了亚油酸(LA)、油酸(OA)、棕榈酸(PA)含量与掺假浓度之间的关系。结果显示,掺假浓度与 LA 含量之间存在较强正相关关系(图 6b),其相关系数 R 达 0.75。在特定波段(525 nm、552 nm 和 609 nm)处,光谱数据与掺假浓度之间表现出显著正相关(图 6a),偏相关系数 p ≤ 0.001。此外,LA 与 OA 含量之间呈强负相关关系,相关系数 R= −0.87,说明当 LA 含量升高时,OA 含量也随之升高。进一步地,将三种脂肪酸含量与预处理后的光谱数据(MF)一同输入多元回归模型,以探索其内在关系。可明显看出在将脂肪酸含量作为建模特征后,整体模型性能显著提升,所有模型的 R² 值均达到 0.9 以上,尤其是 Stacking 模型的 R² 达到 0.976,显示出*佳的预测性能。随后,采用 Stacking 算法对油样数据进行测试,测试集包括88个掺假浓度在 0% 至 100% 之间的额外样本。整体预测绝*误差较小,*大偏差为 16.64%,最小偏差为 0.01%。结果表明,Stacking 模型在不同油样掺假水平预测中表现良好,验证了其在实际应用中的可靠性与有效性,为食品行业中的真实性检测提供了有力技术支持。
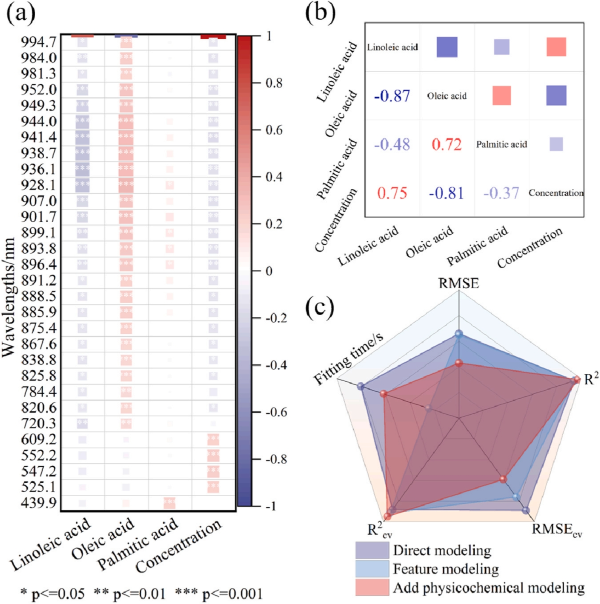
图6. 光谱特征波段与不同浓度脂肪酸的联合分析(a) 不同掺伪浓度下光谱特征波段与脂肪酸含量的相关性分析(b) 掺伪浓度与脂肪酸含量的相关性分析(c) 不同模型性能对比雷达图
本研究提出了一种基于HSI和GC-MS技术的化学计量学方法,用于检测红花籽油(SSO)的掺假浓度。通过不同的预处理方法,研究发现采用MF进行预处理能够成功降低噪声信息,并显著提升模型的稳健性和泛化能力。此外,本研究还确定了特定的波长范围(接近440nm、530nm以及880nm至950nm),这些波长范围能够在不降低预测准确性的前提下优化建模时间。在开发模型的过程中,构建的集成学习模型(包含Ridge、PLSR基础模型以及LightGBM元模型)在预测红花籽油浓度掺假方面展现出比单一模型更高的准确率。特别是通过联合建模GC-MS测定的脂肪酸含量和高光谱数据,模型的决定系数提升至0.976,进一步凸显了该模型的卓越性能。因此,MF-Ridge-Stacking模型被确定为预测红花籽油掺假浓度的*佳模型。本研究拓展了红花籽油及其他食用油掺假的识别方法,并通过结合GC-MS和HSI技术以及机器学习,为食品行业提供了一种实用且可靠的掺假检测方法。
 地址:无锡市梁溪区南湖大道飞宏路58-1-108
地址:无锡市梁溪区南湖大道飞宏路58-1-108
.png) 电话:13810664973
电话:13810664973
.png) 邮箱:info@dualix.com.cn
邮箱:info@dualix.com.cn
地址:北京市海淀区中关村大街19号
电话:13810664973
邮箱:info@dualix.com.cn
地址:陕西省西安市高新区科技一路40号盛方科技园B座三层东区
电话:13810664973
邮箱:info@dualix.com.cn
地址:成都市青羊区顺城大街206号四川国际大厦七楼G座
电话:13810664973
邮箱:info@dualix.com.cn
地址:深圳市龙华区民治梅龙路电话:13810664973邮箱:info@dualix.com.cn
 在线咨询
在线咨询