
背景
烟草生产是中国西南地区农业和农村经济发展的关键支柱。为了给烟叶质量优化提供信息支持,减轻烟农的劳动负担,对快速、准确、实时的叶片氮含量(Leaf nitrogen content, LNC)检测方法有很大需求。无人机机载高光谱遥感(Hyperspectral remote sensing, HRS)能够以非破坏性的方式获取成像光谱数据,实现烟叶LNC的快速获取。
一般来说,可以使用经验方法或物理方法建立模型,或者两者相结合,以实现目标性状的反演。为了解决单个反演方法的异质性,一些学者提出了作物表型性状估计的集成学习框架。与试图从训练数据中学习一个假设的普通机器学习方法不同,集成方法试图构建一组假设并将它们组合起来使用。集成学习的思想是结合几种不同的方法来增强输入的多样性,以挖掘更多的数据特征,从而提高模型的整体性能。
本研究旨在建立一种准确有效的模型,利用无人机机载高光谱图像估计烟草LNC。研究中测试了几种基于三种集成学习策略的典型算法,包括随机森林(RF)回归、自适应增强(Adaboost)回归和堆叠回归。此外,我们选择了*常用的偏*小二乘回归(PLSR)作为基准模型。主要创新点有:(1)研究了无人机机载HRS在烟草LNC估算中的潜力;(2)评估了不同集成学习策略(如bagging、boosting和stacking)下模型的性能;(3)探索基于堆叠策略提高模型预测精度的可行方法。
试验设计
江苏大学赵春江教授团队利用Gaiasky-Mini-VN高光谱相机(江苏双利合谱公司)获取了研究区内不同氮处理下烟草冠层的高光谱影像,其波段范围为400 ~ 1000 nm,波段数为256。各类地物的光谱曲线如图1所示。在整个田间试验过程中,每约20天采集一次冠层图像,从移栽后35天开始,一直持续到收获。
影像获取后,第一步,利用ExG去除背景,并提取平均反射率。第二步,利用连续投影算法(SPA)进行数据降维。第三步,建立LNC估计模型,研究中选择了*常用的PLSR作为基准模型(图1)。此外,采用集成学习方法来完成上述相同的回归任务。集成学习框架下有三种建模策略,即bagging、boosting和stacking。本研究以决定系数(R2)、均方根误差(RMSE)和平均绝对百分比误差(MAPE)作为评价指标。
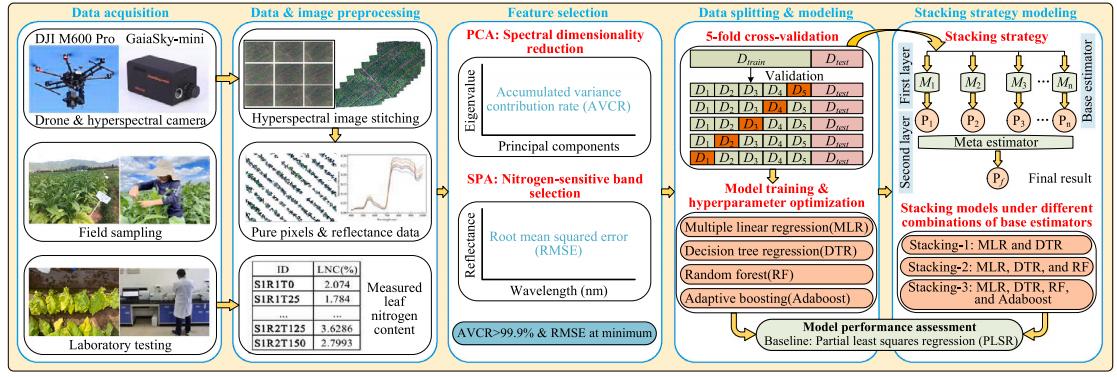
图1 本研究主要步骤流程图
结论
本研究对全波段高光谱反射率数据进行主成分分析(PCA),提取对LNC变化更敏感的主成分(PC)。如图2所示,选取前80个PC进行显示,当主成分数为4、6、7时,累积方差贡献率(AVCR)分别超过99.5%、99.8%、99.9%。我们选择SPA作为二次降维算法。与PCA不同,SPA可以通过选择对LNC变化更敏感的变量来降低数据维度,*终保留了15个波段(图3)。
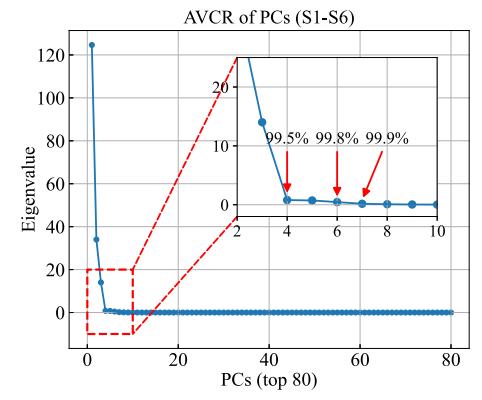
图2 前7个PC贡献了超过99.9%的信息
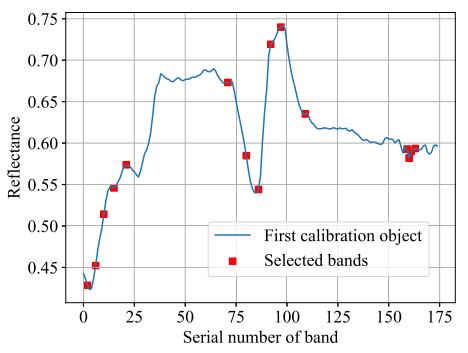
图3 选择的15个波段
从图4可以看出,PLSR的R2相对较低,但训练集与测试集之间的差距较小。由于PLSR结合了PCA和MLR。在这里,我们也给出了MLR的预测结果,训练集和测试集之间的差距也很小(图4c、4d)。结果表明,训练良好的MLR模型具有良好的稳定性,样本分布均匀,同时也证明了我们的数据集划分是合理的。
图4g – 4p显示了集成学习方法的结果,包括RF、Adaboost和堆叠模型。RF和Adaboost都是基于决策树回归(DTR),为了避免过拟合,我们将max_dept的值设置为5。DTR的预测结果如图4e和图4f所示。对于堆叠模型,我们采用双层结构,MLR和DTR模型(即stacking – 1)作为第一层的基估计器,MLR作为第二层的元估计器。结果表明,stacking - 3模型预测效果*好。与DTR模型在测试集上的预测结果相比,stacking - 1模型得到了显著增强,但相较于SPA-MLR改进幅度较小。结果表明,叠加策略可以传递基估计器的优点。通过组合多个模型来挖掘更有价值的数据特征。在图4m - 4p中也可以看到类似的现象。通过将已经训练好的模型添加到堆叠框架的第一层,可以发现在最终表现上也有逐渐的改善。当添加RF模型时(stacking – 2),测试集上的R2不仅从0.710提高到0.743,而且超过了RF本身的R2值,RMSE值也有小幅下降。当Adaboost模型被添加时(stacking – 3),与stacking – 2相比,准确度只有轻微的提高。
综上所述,stacking - 3模型的R2和RMSE最高(0.745, 4.824 mg/g),Adaboost模型的MAPE最小(17.56%)。原因可能是堆叠方法可以从不同的模型中提取更多可用的数据特征。由于数据噪声的存在,模型在数据特征上往往表现不同。堆叠法可以提取各模型中表现较好的特征,丢弃较差的特征,有效地优化预测结果,提高最终的预测精度。Adaboost模型可以根据每个基估计器的预测误差调整其权重。错误率小的基估计器在最终结果中占有较大的权重。因此,Adaboost模型得到最小的MAPE。对于RF,基估计量相互独立,最终结果是所有基估计量的简单平均值,因此RF模型更容易受到异常值的干扰。

图4 训练集和测试集下不同模型性能比较
进一步分析每个基估计器对最终结果的贡献。我们首先选择已经训练好的RF和Adaboost模型作为基估计器(图5a、b)。stacking - 4的综合性能优于RF。将DTR和MLR分别加入到stacking - 4模型中,得到stacking - 5和stacking - 6模型。结果如图5c、f所示。stacking - 5和stacking - 6模型之间存在非常小的差异。同时,stacking - 4模型(R2 = 0.876)和stacking - 6模型(R2 = 0.779)在训练集上存在显著差异。
从某种意义上说,DTR、RF和Adaboost模型(基于树的模型)是同质的,因为DTR本身是RF(bagging & DTR|)和Adaboost(boosting & DTR)模型的基估计器。因此,添加DTR不能使模型挖掘更多可用的数据特征。这可能就是stacking - 5模型的性能变化不大的原因。对于线性模型(MLR),它与基于树的模型原理是不同的,可以学习到一些新特征。虽然在测试集上的表现略有下降,但在训练集上取得了进步。模型的整体稳定性得到了提高。综上所述,RF和Adaboost几乎贡献了所有的堆叠精度,然后MLR有助于提高模型的稳定性。
最后,对如何正确配置堆叠模型提出了一些建议。理想情况下,堆叠策略的第一层中的基估计器应该是“准确和异构的”。通过这种方式,可以学习更多有价值的数据特征。此外,为了避免过拟合,第二层的元估计器通常选择一个简单的模型(线性或岭回归),该模型使用第一层的输出作为训练的输入。
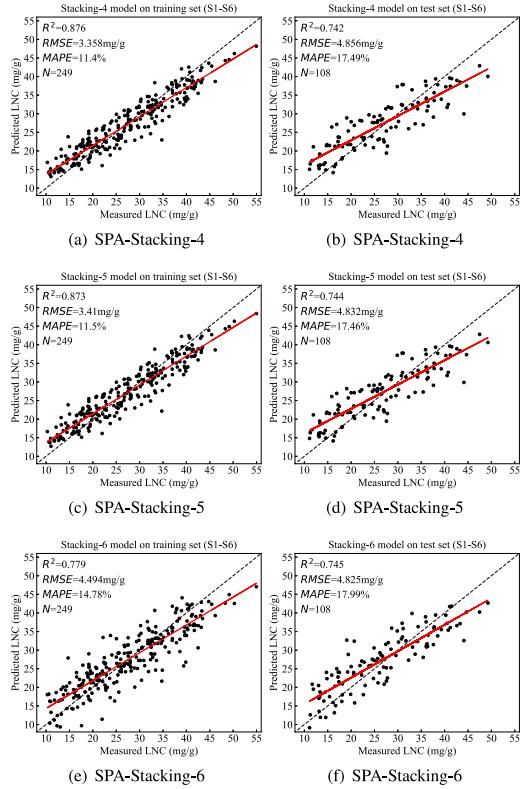
图5 进一步分析堆叠策略
作者信息
赵春江,博士,江苏大学农业工程学院教授,博士生导师。
主要研究方向:农业智能系统与精准农业技术装备。
参考文献:
Zhang, M.Z., Chen, T.E., Gu, X.H., Kuai, Y., Wang, C., Chen, D., & Zhao, C.J. (2023). UAV-borne hyperspectral estimation of nitrogen content in tobacco leaves based on ensemble learning methods. Computers and Electronics in Agriculture, 211.
https://doi.org/10.1016/j.compag.2023.108008
 地址:无锡市梁溪区南湖大道飞宏路58-1-108
地址:无锡市梁溪区南湖大道飞宏路58-1-108
.png) 电话:13810664973
电话:13810664973
.png) 邮箱:info@dualix.com.cn
邮箱:info@dualix.com.cn
地址:北京市海淀区中关村大街19号
电话:13810664973
邮箱:info@dualix.com.cn
地址:陕西省西安市高新区科技一路40号盛方科技园B座三层东区
电话:13810664973
邮箱:info@dualix.com.cn
地址:成都市青羊区顺城大街206号四川国际大厦七楼G座
电话:13810664973
邮箱:info@dualix.com.cn
地址:深圳市龙华区民治梅龙路电话:13810664973邮箱:info@dualix.com.cn
 在线咨询
在线咨询