应用方向:
本研究采用高光谱成像技术和深度森林(DF)模型,对不同程度霜害稻种进行快速无损分类。通过优化光谱数据预处理(如多元散射校正MSC)和特征提取算法(如邻域成分分析NCA),构建了多种分类模型,并对比了传统机器学习方法(决策树、KNN、SVM)与DF模型在小样本数据上的表现。结果显示,DF模型具有更高的分类精度和鲁棒性。研究还通过可视化技术直观展示了霜害稻种的分类结果,为农业生产中的种子筛选和质量控制提供了高*、智能化的解决方案。该方法不仅提高了霜害种子检测精度,也为高光谱成像在精准农业中的应用提供了重要参考。
背景:
稻种质量直接影响农业产量,但在生产和储存过程中易受霜害、热害、真*感染等影响,导致活力下降,尤其在中国东北地区,晚熟粳稻种子易受低温霜害,降低发芽率和幼苗生长速率,可能引发农业减产。因此,快速、非破坏性检测霜害种子的技术对农业生产至关重要。
传统检测方法如发芽试验、四唑染色法虽准确,但操作复杂、成本高且具破坏性,难以大规模应用。近年来,光谱成像技术因其能同时获取光谱和图像信息,被广泛应用于种子质量检测,尤其是高光谱成像技术结合化学计量学和机器学习算法,在种子活力和霜害检测方面取得显著成果。
然而,深度学习模型通常需要大量样本和复杂参数设置。为此,本文提出将高光谱成像技术与适用于小样本数据的深度森林模型(DF)结合,用于霜害稻种分类研究。该方法建模简单,对小样本数据具有良好鲁棒性,为霜害稻种识别提供了一种高*解决方案。。
实验设计
1.1材料与方法
本实验使用的水稻种子品种为“艳风”,2018年收获于辽宁盘锦,初始含水量13%至14%(干种子)。随机选取1800粒种子,并人工调整含水量至30%,以研究霜冻损伤。种子被随机分为6组,每组300粒,其中一组为对照组,未冷冻处理,其余5组在不同温度下冷冻不同时间(见表1)。冷冻后,种子在25°C干燥通风环境中放置一周,以恢复正常温度并减少水分干扰。
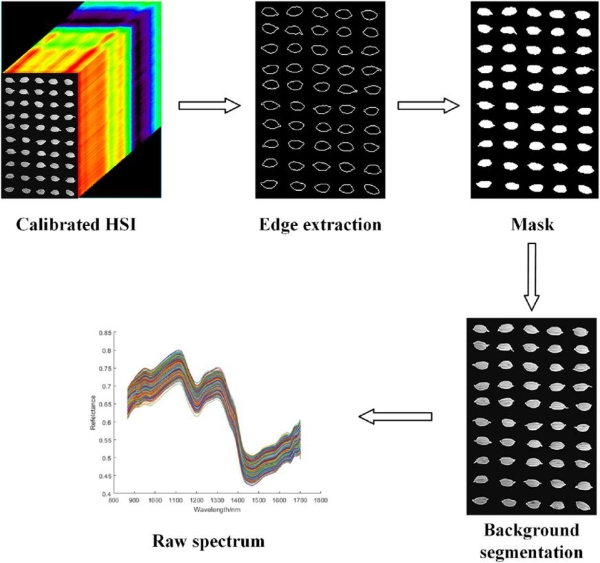
在本实验中,选用了江苏双利合谱科技有限公司的“GaiaSorter”高光谱成像系统。该系统的核心组件包括均匀光源、光谱相机、计算机以及相关的控制软件。在光谱成像仪中使用的相机是“Image-λ”系列高光谱相机,其光谱范围大约为900-1700 nm。系统的工作原理是将待测样品放置在由软件控制的电动移动平台上,并采用推扫法来收集图像。随着电动平台的移动,最终获得了包含待测样品光谱信息和图像信息的高光谱立方体数据。由于原始光谱数据中存在的噪声会干扰后续的数据分析,因此本实验选取SG1、SNV和MSC方法对原始光谱数据进行预处理。
图1. 提取光谱数据的主要流程图。
在获取高光谱图像之后,从每组中随机选取50粒水稻种子,并根据国际种子检测协会(ISTA)的规则进行发芽测试。我们将种子浸泡在蒸馏水中12小时,然后在标准发芽箱中进行种子发芽测试,并在种子表面覆盖湿润的发芽纸以在室温25°C下遮光。发芽力(GF)和发芽率(GR)是反映种子质量的主要指标之一。通常情况下,具有高GR和GF的种子活力强,而GR高但GF低的种子也可能活力低下。
原始光谱数据高维且含冗余信息,难以直观区分样本差异。本研究采用t-SNE方法将高维数据映射至低维,实现样本可视化,并扩大簇间距离以缓解拥挤问题。此外,高光谱数据的冗余和共线性影响模型性能,因此使用PCA、SPA和NCA提取特征波长。PCA将多个指标转化为少数主成分以降低维度,SPA通过前向变量选择去除冗余信息,NCA作为度量学习算法,优化数据的空间表示,提高模型效果。
本研究利用决策树(DT)、K最近邻(KNN)、支持向量机(SVM)和深度森林(DF)四种模型对水稻种子进行分类评价,确保分类的准确性与泛化能力。DT通过构建决策树确定分类概率,并采用交叉验证优化最小叶节点(minleaf)值。KNN依据邻近样本类别进行分类,并通过自动优化程序确定*佳k值。SVM采用RBF核函数处理线性和非线性数据,并利用网格搜索优化惩罚系数(c)和核函数半径。DF通过级联森林结构进行表示学习,并在验证集上评估性能,若无显著提升则终止训练,以控制模型复杂度。
1.2.结果与讨论
(1)发芽试验结果分析
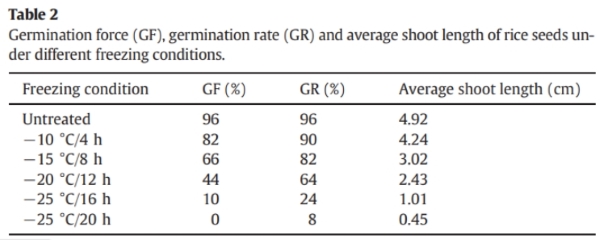
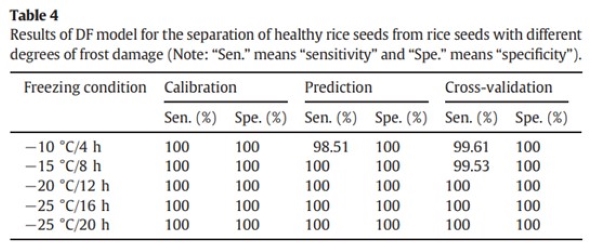
表2显示,不同冷冻条件下水稻种子的发芽势(GF)、发芽率(GR)和平均芽长均下降。正常种子的GF与GR一致,而霜冻*害种子的GF低于GR。GR高且GF强表明幼苗出土快且整齐,GF弱则出土不均且幼苗弱。在-10°C/4小时下,GR达90%,GF仅82%,且平均芽长较短,表明轻微霜冻*害。这些种子播种后出苗不足,影响收成,因此快速无损识别霜冻*害种子对农业生产至关重要。
(2)原始光谱分析
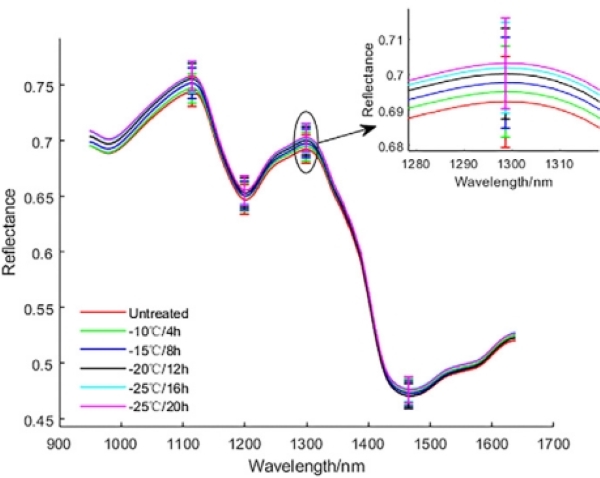
原始光谱波长范围为900-1700 nm,但受仪器影响,前后部分噪声较大。因此,我们选取了949.0-1638.0 nm的210个波长进行分析。图3显示不同冷冻条件下水稻种子的平均光谱曲线和标准差。六组种子的光谱曲线趋势相似,但在特定波长范围内存在显著差异。例如,在1000.0-1300.0 nm,光谱反射率依次递减:-25°C/20 h > -20°C/16 h > -15°C/12 h > -10°C/8 h > -10°C/4 h > 未处理,其中1300 nm处差异最明显。1000-1100 nm主要对应N/H伸缩的第三泛音,1100-1300 nm对应C/H伸缩的第二泛音。随着冷冻温度和时间增加,种子细胞受损,淀粉结构破坏,影响糊粉层和胚的结构,阻碍赤霉素进入,进而影响种子活力。因此,冷冻条件越严苛,细胞破坏越严重,使得1000-1300 nm的光谱反射率逐渐增加。
图3. 不同冷冻条件下水稻种子的平均光谱曲线及其标准差
(3)高维光谱数据的可视化分析
本研究采用t-SNE对原始光谱数据及SG1、SNV、MSC三种预处理方法处理后的光谱数据进行可视化,并将其降维至二维进行分析比较。为减少t-SNE的随机性,采用Matlab R2018b默认参数(欧几里得距离、Perplexity = 30、LearnRate = 500、Theta = 0.5)。
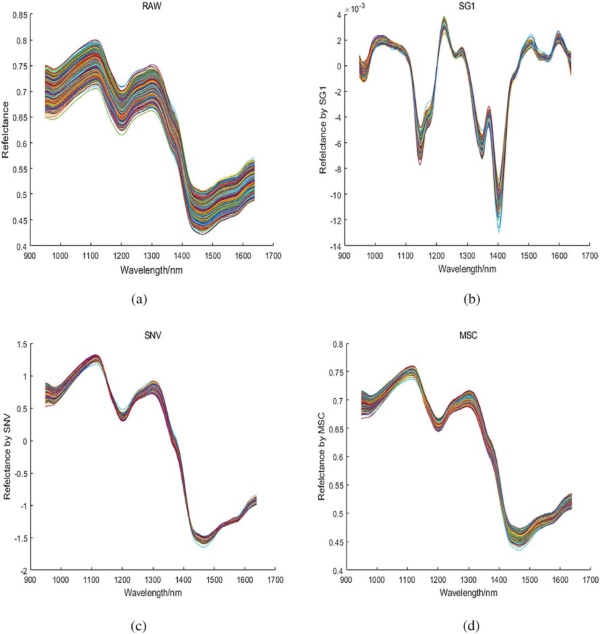
图4展示了不同预处理方法的光谱曲线及t-SNE可视化结果。从图4e可见,原始光谱数据在不同冷冻条件下混合重叠,降维后特征难以区分。图4f和4g显示,SG1和SNV处理后仍存在大量重叠,与原始数据相比无明显改善。而图4h表明,经MSC预处理的数据聚类效果显著,6组水稻种子被清晰分类。总体而言,MSC处理后的光谱数据优于其他方法。
图4. 不同预处理方法的光谱曲线:(a) 原始光谱曲线;(b) SG1处理后的光谱曲线;(c) SNV处理后的光谱曲线;(d) MSC处理后的光谱曲线。使用t-SNE可视化不同预处理方法处理的光谱数据:(e) 原始光谱数据;(f) SG1处理后的光谱数据;(g) SNV处理后的光谱数据;(h) MSC处理后的光谱数据。
(4)基于全波长的建模分析
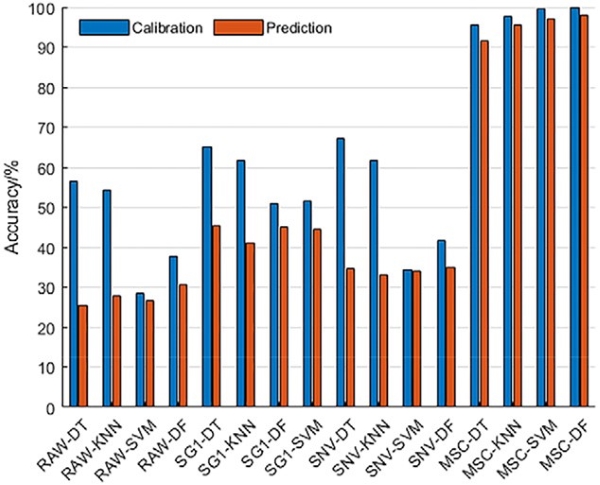
在建模前,所有样本随机分为校准集和预测集,比例为3:1。为了选择*佳的预处理方法和模型组合,将原始光谱数据以及经过SG1、SNV和MSC预处理的光谱数据分别输入到DT、KNN、SVM和DF模型中。图5显示了基于全波长的建模分析结果。可以看出,经过MSC处理的光谱数据具有最高的建模准确率,均高于90%。这与t-SNE可视化的结论一致。
图5. 基于全波长建模分析的结果
(5)基于PCA、SPA和NCA的特征波长选择
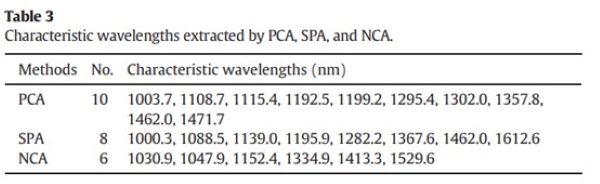
为降低高维光谱数据维度并保留关键信息,本研究采用PCA、SPA和NCA从MSC处理后的光谱数据(210个变量)中提取特征波长。前三个主成分的累积贡献率达99.52%,因此选取其载荷系数提取特征波长。图6显示了提取结果,共选出10个关键波长(1003.7、1108.7、1115.4、1192.5、1199.2、1295.4、1302.0、1357.8、1462.0和1471.7 nm)。
图6. 利用前三个主成分载荷曲线提取的特征波长。
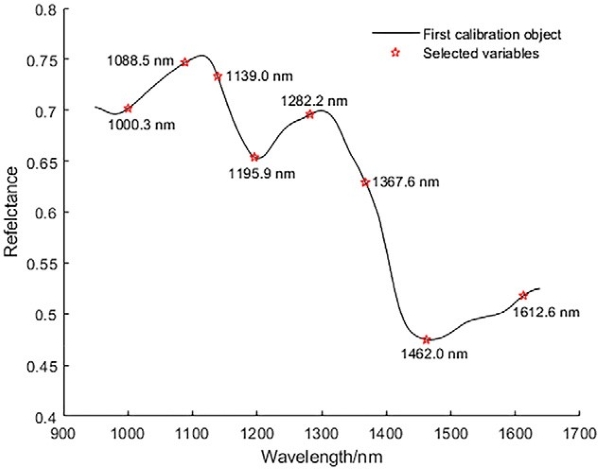
图7展示了SPA选择的特征波长结果。最终,选择了8个特征波长,根据它们相关性的顺序排列依次是1139.0、1088.5、1000.3、1195.9、1282.2、1612.6、1367.6和1467.0 nm。这些波长的相关性也显示了它们在区分不同霜冻程度水稻种子中的重要性。
图7. 由SPA提取的特征波长。
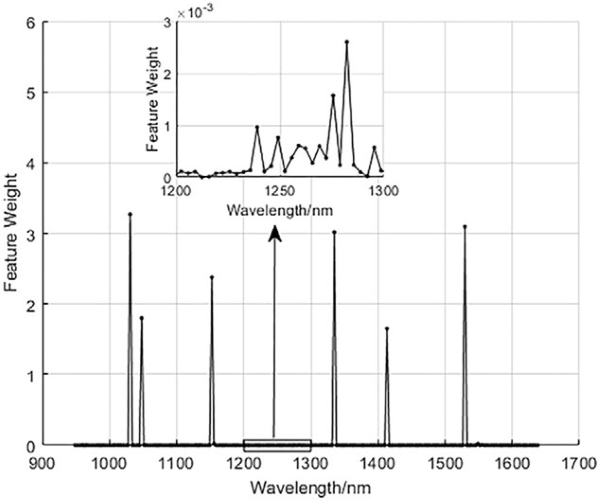
NCA算法用于高维数据特征选择,通过计算变量权重筛选重要特征。图8显示,在210个波长中,仅6个波长权重显著高于0,表明多数波长对区分霜冻程度贡献较小。最终选出的六个特征波长依次为1030.9、1529.6、1334.9、1152.4、1047.9和1413.3 nm,它们与水稻种子化学成分密切相关。
图8. 使用NCA获得的每个波长的权重值。
表3展示了三个特征提取算法提取的特征波长。可以看出,PCA和SPA提取的特征波长非常接近,NCA算法提取的特征波长数量最少。
(6)基于特征波长的建模分析
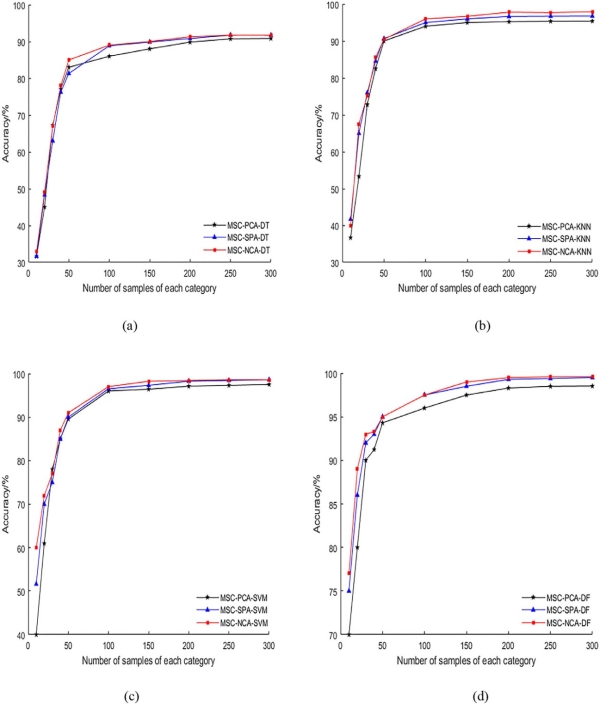
为了评估不同模型的有效性,我们将总样本集(6类水稻种子,每类300粒,共1800粒)分成不同样本集,包含每类水稻种子10至300粒不等。模型的准确率通过五折交叉验证获得。图9a至d展示了基于DT、KNN、SVM和DF模型在不同样本集数量下的结果。整体上,PCA的效果不如NCA和SPA。在比较后发现,当样本集较少时,NCA提取的特征波长建模效果优于SPA,且随着样本集增加,二者的效果趋于接近。此外,NCA提取的特征波长数量少于SPA,有助于提升运算速度。因此,NCA被选为*佳特征提取算法。
图9. 基于不同特征提取算法在不同样本集数量下的建模结果。(a) DT模型;(b) KNN模型;(c) SVM模型;(d) DF模型。
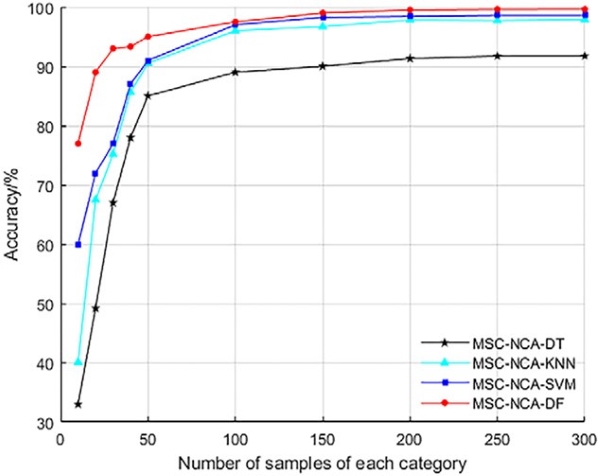
图10展示了基于NCA的DT、KNN、SVM和DF模型在不同样本集数量下的建模结果。DF模型在样本数量较少时仍保持了良好的分类效率,显著高于本其他三个模型。同时,由于DF模型在不同样本集数量下的分类准确率优于其他三个分类模型,因此最终被选为*佳分类模型。
图10. 基于NCA的不同样本集数量下DT、KNN、SVM和DF模型的建模结果
(7)不同霜冻程度水稻种子的可视化
高光谱成像技术能够同时获取水稻种子的光谱和空间信息,从而通过可视化地图展示不同霜冻程度的种子分类结果。研究采用逐对象方法进行可视化,并从1500粒种子(每类250粒)中选取样本进行模型校准和测试,剩余300粒用于可视化。基于MSC-NCA-DF模型,校准时将种子随机分为校准集和预测集,并通过5折交叉验证验证模型效果。通过敏感性和特异性评估模型性能。DF模型能够高*区分健康和不同霜冻程度受损的种子,表明其具有较高的敏感性和特异性。视觉分类结果显示,在300粒种子中,只有2粒被误分类,分类准确率为99.33%。
图11. 不同霜冻程度水稻种子分类结果的可视化。
结论
本研究结合DF模型和高光谱成像技术,成功识别不同霜冻程度受损的水稻种子。使用三种光谱预处理方法、三种特征提取算法和三种传统机器学习模型,以及一个深度学习模型进行对比建模。经过分析,MSC-NCA-DF模型表现*佳,DF模型在小样本集中依然具备良好分类能力,最终被选为*佳模型。基于该模型的分类结果可视化,展示了不同霜冻程度的水稻种子,为未来在线检测系统提供参考。
推荐产品
作者简介
通讯作者:吉海彦,中国农业大学,博导
参考文献
论文引用自一区文章:Liu Zhang, Heng Sun, Zhenhong Rao, Haiyan Ji. Hyperspectral imaging technology combined with deep forest model to identify frost-damaged rice seeds. Spectrochimica Acta Part A: Molecular and Biomolecular Spectroscopy 229 (2020) 117973. https://doi.org/10.1016/j.saa.2019.117973


.jpg)


 地址:无锡市梁溪区南湖大道飞宏路58-1-108
地址:无锡市梁溪区南湖大道飞宏路58-1-108.png) 电话:13810664973
电话:13810664973.png) 邮箱:info@dualix.com.cn
邮箱:info@dualix.com.cn
 在线咨询
在线咨询