
背景
高粱在发展中国家作为食粮作物, 在田间种植过程中需要喷撒农药以减少病虫害对于产量和品质的影响。当出现严重的病虫害时, 农户们会多次喷洒高浓度的农药溶液, 这导致高粱中存在过量的农药残留。研究表明, 长期食用农药残留超标的食物对人体危害巨大, 会造成癌症、心脏病、神经性疾病等严重后果。因此, 如何无损、快速、准确检测高粱中的农药残留是亟待解决的问题。
高光谱技术相比于传统的光谱技术, 可以同时获得检测样品的图像信息和光谱信息, 可以实现对农药残留的准确检测。本研究建立了基于BP神经网络自适应增强算法的集成学习高粱农药残留分类模型, 相比于单一分类模型, BP-AdaBoost结合BP神经网络和AdaBoost算法的优势, 可以适应不同的数据和问题, 提高模型分类正确率、减少模型过拟合风险。本研究结合高光谱技术与机器学习算法快速检测高粱中残留的农药种类, 可以帮助农产品生产者和食品加工厂快速识别高粱中的农药残留种类。
实验设计
本研究所使用的高粱品种为红缨子, 是贵州某高粱育种中心常见的品种。农药选择高粱种植过程中常用的农药种类, 分别为苯醚甲环唑、马拉硫磷、氯虫苯甲酰胺、莠去津, 分别表示为B、M、L、Y, 购买于四川宜宾某农药市场。4种农药分别用蒸馏水稀释400、700、700、200倍, 配制实验所需的农药溶液。用4个喷壶农药溶液均匀喷洒在4组高粱样品上, 并设置一组喷洒清水(Q)样品的对照组。每组样品包含2880颗高粱籽粒, 共计14400颗。将高粱样品放置于室内通风处, 自然干燥12 h后利用GaiaField-N17E-HR高光谱成像系统(江苏双利合谱公司)采集高粱样品的高光谱图像。

图1高光谱成像系统
采用分水岭算法分割高粱样品籽粒,将每颗高粱籽粒所在区域作为感兴趣区域提取光谱信息。使用孤立森林算法剔除光谱中的异常值,利用SNV、SG和DWT对光谱数据进行预处理,通过CARS、PCA、CatBoost和GBDT筛选特征波长,建立了XGBoost、LGBM、SVM和 BP-Adaboost农药残留分类模型,实现了高粱农药残留种类的快速无损检测。
结论
为显示不同种类农药残留高粱样品光谱曲线的差异, 计算每类高粱样品的光谱曲线的平均值得到平均光谱曲线, 如图2所示。由图2中可以看出, 在近红外波段范围内, 光谱曲线出现3处较为明显的吸收峰, 分别位于925 nm、1230 nm、1470 nm左右。925 nm位置处的吸收峰与O-H的第一拉伸泛频有关, 1230 nm位置处的吸收峰与C-H的第二拉伸泛频有关, 1470 nm位置处的吸收峰与N-H的第一拉伸泛频有关。在近红外波段范围内, 各类农药残留高粱样品的光谱反射率不同, 但总体变化趋势相似。无农药残留高粱样品的反射率最低, 与不同类型农药残留样品的光谱曲线差异最明显。此外, B与Y的平均光谱反射率非常接近, L的平均光谱反射率最高。在1000~1100 nm范围内, 各类高粱样品的反射率差距最大, 由高到低分别是L、M、Y、B、Q。这些平均光谱的差异为鉴别高粱样品农药残留种类提供了依据。
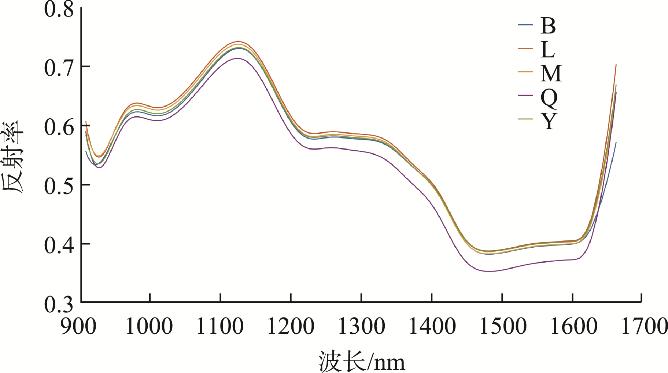
图2 高粱农药残留样品平均光谱曲线
高粱农药残留样品的光谱曲线在900 nm和1700 nm处出现了异常波动, 这说明这两个位置处的光谱数据受到的干扰较大, 数据存在严重失真的情况。为消除数据失真对后期建模分类效果的影响, 本研究截去了光谱数据开始处前15个和末尾处后41个波段信息, 保留456个波段用于建模分析。利用SG、DWT、SNV预处理方法对高粱农药残留样品的光谱数据进行预处理。建立预处理光谱数据的SVM农药残留分类模型识别农药残留种类, 识别结果如表1所示。结果显示, 使用SNV预处理的光谱数据建立的分类模型识别效果好, 训练正确率和测试集正确率分别为85.94%和81.58%。这可能是SNV预处理可以同时减少噪声和散射成分对光谱数据的影响。因此, 将SNV预处理后的光谱数据用于后续的研究分析中。原始光谱曲线如图3(a)所示,SNV预处理之后的高粱农药残留样品光谱曲线如图3(b)所示。
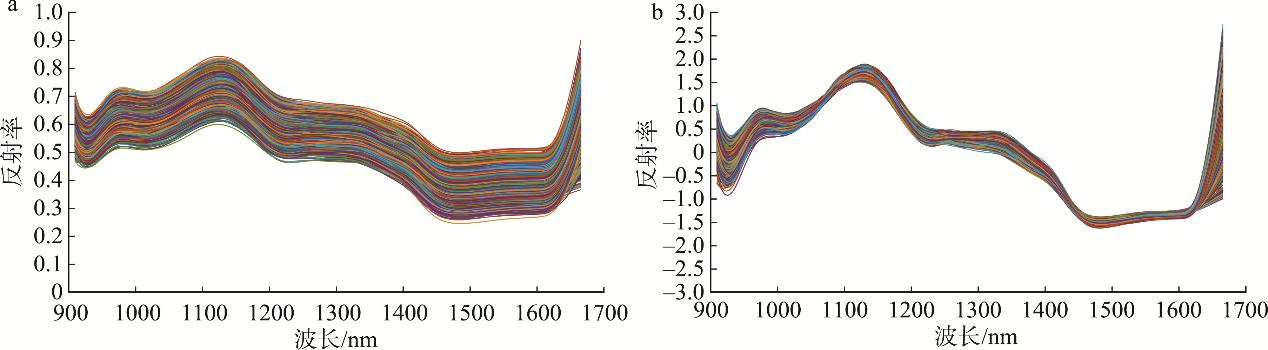
注: a: 原始光谱曲线; b: SNV预处理后的光谱曲线
图3 高粱农药残留样品光谱曲线
表1 光谱数据预处理后的建模效果(%)
|
方法 |
训练集正确率 |
测试集正确率 |
|
原始光谱(未处理) |
82.67 |
81.11 |
|
SG |
82.77 |
81.43 |
|
DWT |
82.53 |
81.46 |
|
SNV |
85.94 |
81.58 |
本研究使用了CatBoost、GBDT、CARS、PCA特征选择方法, CatBoost和GBDT通过设置特征重要性得分阈值(0.2)选择特征波长, PCA通过设置载荷系数阈值(0.1)选择特征波长, CARS选择建立最小交叉验证均方根误差(root mean square error of cross validation, RMSECV)值PLS模型的波长为特征波长, 分别选择了132、147、35、12个特征波长。图4为特征波长的具体位置分布图, 在图4(a)和图4(b)中, 绿色线条代表特征波长的具体位置, 红色线条代表所选择特征波长对应的特征重要性得分, 特征波长大致分布在900、1100、1400、1650 nm范围内。其中, CatBoost提取的最大贡献率波长分布在1600 nm左右, 特征重要性得分为10.23%, GBDT提取的最大贡献率波长分布在1400 nm左右, 特征重要性得分为4.11%。在图4(c)和图4(d)中,红色线条代表特征波长的具体位置。
表2 特征方法的建模结果(%)
|
模型 |
特征方法 |
训练集正确率 |
测试集正确率 |
|
SVM |
None |
85.94 |
81.58 |
|
CatBoost |
82.40 |
81.87 |
|
|
GBDT |
82.04 |
81.30 |
|
|
CARS |
77.34 |
76.47 |
|
|
|
PCA |
60.68 |
59.19 |
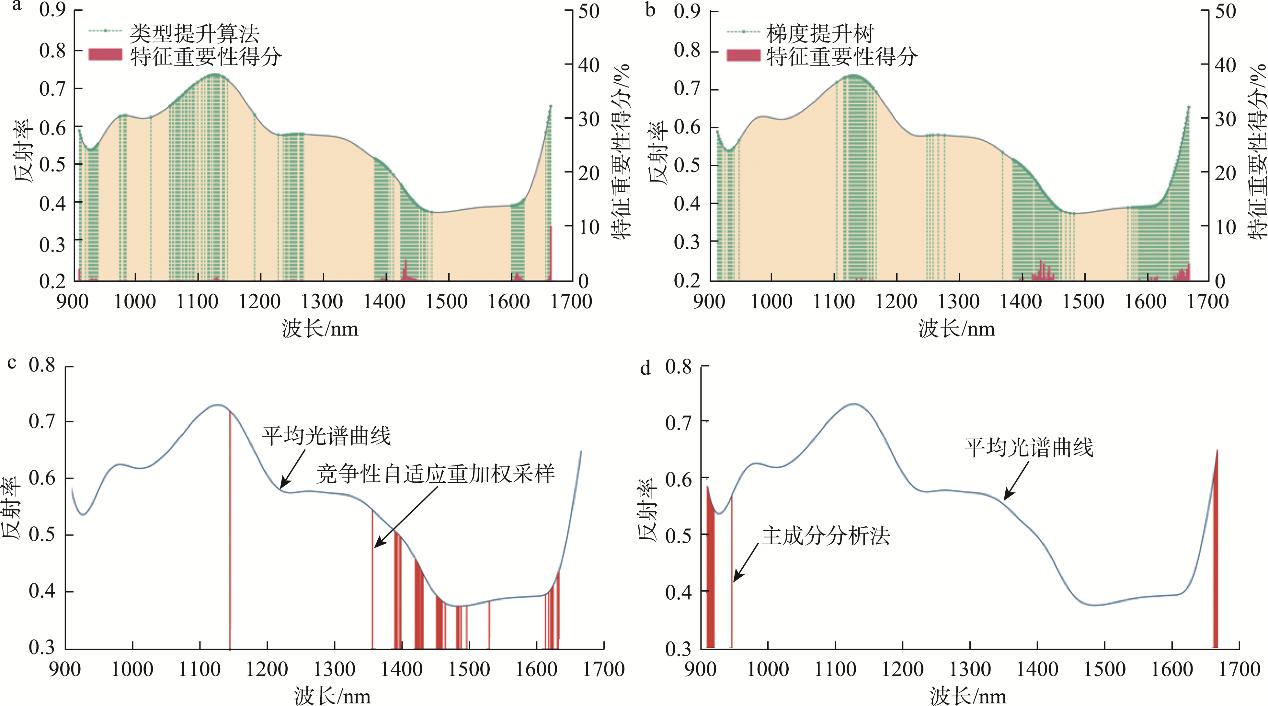
注: a: CatBoost; b: GBDT; c: CARS; d: PCA
图4 特征波长分布位置
使用CatBoost算法选择的特征波长为光谱数据, 以实际农药残留种类为标签, 建立光谱数据集, 并使用样品集划分方法将光谱数据集划分为训练集和测试集, 建立了BP-Adaboost、XGBoost、LGBM、SVM模型, 实现高粱中不同类别的农药残留的分类, 建模结果如表3所示。从整体分类结果可以看出, Q的分类正确率最高, 识别效果好, Y的分类正确率最低。最佳的农药残留分类模型为BP-Adaboost, 测试集平均分类正确率为95.17%, B、L、M、Q、Y测试集分类正确率分别为99.80%、85.11%、94.76%、99.80%、96.24%, 错误识别农药残留高粱籽粒颗数分别为1、74、24、1、19。相比于XGBoost、LGBM、SVM模型, BP-Adaboost模型平均正确率分别提升了12.66%、13.47%、13.3%。BP-Adaboost模型之所以取得如此良好的分类结果, 是因为它不仅利用弱分类器组合形成强分类器, 而且还利用BP神经网络来调整输入值与输出值之间的误差。XGBoost与LGBM模型训练集分类正确率为100%, 但测试集分类正确率却较低, 模型出现过拟合现象。本研究针对这个情况使用网格寻优来调整模型的参数, 但分类效果仍然没有提升, 这可能是由于模型的复杂程度过高而导致的模型过拟合。此外, BP-Adaboost模型建模时间为124.79 s, 虽然相比于XGBoost等模型所需较长, 但与全波长建立的BP-Adaboost模型相比(建模时间为3325.34 s), 极大地降低了模型训练的时间。与相比姜荣昌等[13]的研究, 在保证单一农药残留类别识别率高的基础上, 同时又提升了模型平均分类正确率。总体来说, CatBoost特征选择方法结合BP-Adaboost模型可以准确鉴别高粱农药残留种类。
本研究利用IF算法剔除了高粱光谱数据集中的异常值, 减少了异常样品对于建模结果的影响; 使用SNV预处理方法对光谱数据进行预处理, 减少了噪声和散射成分对于光谱信息的干扰; 在特征波长选择方面, 使用CatBoost特征选择方法, 通过计算波长的特征重要性选择特征波长, 降低了冗余信息对于分类结果的影响, 加快了模型的训练速度, 特征波长建模效果优于PCA、CARS和GBDT选择的特征波长; 最重要的是使用BP-Adaboost集成学习模型, 结合BPNN与AdaBoost方法, 对多个弱分类器的结果进行集成, 提高了模型的分类正确率, 成功地识别出4组不同农药残留的高粱样品和一组无农药残留的高粱样品, 其中B和Q的分类正确率均为99.80%, 与XGBoost、LGBM、SVM模型相比分别高出了12.66%、13.47%、13.3%, 充分体现出集成学习模型的优势。综上所述, 本研究提出了一种新高粱农药残留识别方法, 融合高光谱成像技术、CatBoost特征选择方法和BP-Adaboost集成学习模型, 成功的实现了高粱农药残留的快速、无损识别, 模型训练集平均分类正确率为95.68%, 模型测试集平均分类正确率为95.17%, 为农产品中的农药残留种类提供了一种高效、准确的分类解决方案。
表3 特征波长建模结果
|
模型 |
类别 |
训练集正确率/% |
训练集平均正确率/% |
测试集正确率/% |
测试集平均正确率 |
时间/s |
|
BP-Adaboost |
B |
99.55 |
95.68 |
99.80 |
95.17 |
124.79 |
|
L |
86.13 |
85.11 |
||||
|
M |
95.74 |
94.76 |
||||
|
Q |
99.95 |
99.80 |
||||
|
Y |
96.86 |
96.24 |
||||
|
XGBoost |
B |
100.00 |
100.00 |
96.39 |
82.51 |
45.49 |
|
L |
100.00 |
77.47 |
||||
|
M |
100.00 |
73.91 |
||||
|
Q |
100.00 |
99.62 |
||||
|
Y |
100.00 |
63.07 |
||||
|
LGBM |
B |
100.00 |
99.55 |
97.41 |
81.70 |
47.82 |
|
L |
98.62 |
73.68 |
||||
|
M |
99.59 |
76.16 |
||||
|
Q |
100.00 |
99.17 |
||||
|
Y |
99.54 |
63.16 |
||||
|
SVM |
B |
97.84 |
82.40 |
97.71 |
81.87 |
47.82 |
|
L |
71.55 |
70.40 |
||||
|
M |
78.12 |
74.58 |
||||
|
Q |
99.44 |
99.61 |
||||
|
Y |
64.44 |
67.00 |
参考文献:
张嘉洪,何林,胡新军等. 基于高光谱成像技术的高粱农药残留种类检测研究 [J]. 食品安全质量检测学报, 2023, 14 (20): 209-217. DOI:10.19812/j.cnki.jfsq11-5956/ts.2023.20.016
 地址:无锡市梁溪区南湖大道飞宏路58-1-108
地址:无锡市梁溪区南湖大道飞宏路58-1-108
.png) 电话:13810664973
电话:13810664973
.png) 邮箱:info@dualix.com.cn
邮箱:info@dualix.com.cn
地址:北京市海淀区中关村大街19号
电话:13810664973
邮箱:info@dualix.com.cn
地址:陕西省西安市高新区科技一路40号盛方科技园B座三层东区
电话:13810664973
邮箱:info@dualix.com.cn
地址:成都市青羊区顺城大街206号四川国际大厦七楼G座
电话:13810664973
邮箱:info@dualix.com.cn
地址:深圳市龙华区民治梅龙路电话:13810664973邮箱:info@dualix.com.cn
 在线咨询
在线咨询